 |
СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ #02/95
| |
Комитет по развитию функциональных возможностей СУБД
Мы будем называть старые иерархические и сетевые системы первым поколением систем баз данных, а современные реляционные системы - вторым поколением. В настоящей работе будут рассмотрены характеристики, которыми должны обладать менеджеры баз данных следующего, уже третьего поколения. Наши требования состоят из трех основных принципов и 13 детальных предложений.
Сетевые и иерархические системы баз данных, широко распространенные в 70-е годы, получили подходящее название - системы баз данных первого поколения. Действительно, это были первые системы, предлагавшие развитую функциональность СУБД в рамках единой системы, с языками определения и манипулирования данными для наборов записей.2) Типичными представителями первого поколения являются системы, основанные на предложениях CODASYL [CODA71] и IMS [DATE86].
В 80-е годы системы первого поколения были существенно потеснены современным семейством реляционных СУБД, называемых системами баз данных второго поколения. Их появление стало важным шагом вперед для многих приложений, так как в этих системах использовались непроцедурные языки манипулирования данными и предусматривалась значительная степень независимости данных. Типичные представители систем второго поколения - DB2, INGRES, NON-STOP SQL, ORACLE и Rdb/VMS.3)
Однако системы второго поколения были сфокусированы на приложениях обработки бизнес-данных и, как указывали многие исследователи, не являлись адекватными решениями для более широкого класса приложений. Системы автоматизации проектирования (САПР), системы CASE и гипертекстовые приложения часто выделяются как примеры, в которых можно было бы эффективно использовать различные СУБД, обладающие специализированными возможностями. Рассмотрим, например, издательскую систему, с помощью которой клиент хочет создать макет газеты, а затем распечатать ее. Для работы этого приложения необходимо хранить сегменты текста, графики, пиктограммы и множество других типов элементов данных, встречаемых в большей части гипертекстовых сред. Поддержка таких элементов данных системами второго поколения обычно сопряжена с немалыми трудностями.
Однако критики реляционной модели не замечают главного. Системы второго поколения не особо хороши и для поддержки большинства приложений обработки бизнес-данных. Возьмем, например, страховое приложение, обрабатывающее требования о выплатах. Ему необходимы традиционные типы данных, такие как имя и размер выплаты каждому застрахованному человеку. Однако, желательно также хранить и образы фотографий события, к которому относится требование о выплате, и факсимиле оригинального рукописного требования о выплате. Подобные элементы данных неудобно хранить в СУБД второго поколения. Более того, вся информация, имеющая отношение к определенному требованию о выплате, объединяется в папку, содержащую традиционные данные, образы и, возможно, процедурные данные. Структура папки часто бывает настолько сложной, что в сравнении с ней элементы данных и агрегированные данные САПР- и CASE-систем кажутся довольно простыми.
Таким образом, почти всем требуется лучшая СУБД, и уже делалось несколько попыток сконструировать прототипы с продвинутыми функциями. Более того, большинство современных поставщиков СУБД работают над значительным расширением функций своих СУБД второго поколения. Удивительна степень единодушия в отношении желаемых возможностей систем следующего, третьего поколения. В настоящей работе мы представим три основных принципа, которыми следует руководствоваться при создании систем третьего поколения. Кроме этого, будут приведены 13 предложений, в которых требования к новым системам будут обсуждены более детально. Целесообразно сопоставить нашу работу с публикациями [ATKI89, KIM90, ZDON90], где предлагаются другие наборы принципов.
Первый принцип касается определения СУБД третьего поколения.
Принцип 1: Помимо традиционных услуг по управлению данными, СУБД третьего поколения обеспечат поддержку более богатых структур объектов и правил.
Управление данными относится к задачам, с которыми современные реляционные системы справляются вполне успешно. Имеется в виду обработка за секунду 100 транзакций с 1000 оперативных терминалов и эффективное выполнение шестипроходных соединений. Более богатая структура объектов характеризует средства, необходимые для хранения и манипулирования нетрадиционными элементами данных (тексты, пространственные данные). Помимо этого, создателям приложений следует предоставить возможность задавать группу правил, касающихся элементов данных, записей и наборов.2) Ссылочная целостность в контексте реляционных баз данных - простой пример такого правила; однако существует множество более сложных правил.
Рассмотрим два простых примера, иллюстрирующих этот принцип. Вернемся к описанному ранее газетному приложению. Оно содержит множество нетрадиционных элементов данных, таких как текст, пиктограммы, карты и рекламные объявления. Следовательно, для него требуются более богатые структуры объектов. Далее рассмотрим расклассифицированные рекламные объявления. Помимо рекламного текста, имеется набор бизнес-информации, относящейся к обработке данных (расценки, количество дней, в течение которых объявление будет печататься, класс, адрес для отправки счета и т.д.). Любой программе автоматического проектирования газеты необходим доступ к этим данным, чтобы решить, какие именно рекламные объявления должны быть включены в подготавливаемый номер. Более того, продажа расклассифицированных рекламных объявлений в крупной газете - стандартное приложение, связанное с обработкой транзакций, для которого нужны традиционные услуги управления данными. Дополнительно есть множество правил, в соответствии с которыми проектируется номер газеты. Например, рекламу Macy нельзя помещать на одну страницу с рекламой Nordstrom. Для перехода к полуавтоматическому и автоматическому проектированию требуется сформулировать и внедрить такие правила. Итак, наш пример показывает,что возникает необходимость управления правилами.
Теперь рассмотрим пример со страховкой. Мы уже говорили о том,что нужно хранить нетрадиционные элементы данных, таких как фотографии и требования о выплате. Более того, внесение изменений в покрытие страховки клиентам - это стандартное приложение по обработки транзакций. Вдобавок страховому приложению требуется обширный набор правил, таких как:
Отменить выплату страховки любому клиенту, выставившему требование о выплате типа Y на сумму X. Увеличить выплату по требованиям, сделанным более чем N дней назад.
Мы кратко рассмотрели два приложения, на примере которых показали, что для успешного решения большинства задач СУБД должна предоставлять услуги в области данных, объектов и правил. Хотя, возможно, на рынке найдется ниша и для систем с меньшими возможностями, для достижения коммерческого успеха в 90-е годы СУБД должна предоставлять сервисы во всех трех перечисленных областях.
Перейдем ко второму фундаментальному принципу.
Принцип 2: СУБД третьего поколения должны включить в себя СУБД второго поколения.
Другими словами, системы второго поколения внесли решающий вклад в двух областях:
И эти достижения не должны быть отброшены системами третьего поколения.
Существует точка зрения, что есть приложения, которым никогда не потребуется выполнять запросы из-за присущей им простоты доступа к СУБД. В качестве примера часто предлагаются САПР [CHAN89]. Таким образом, будущим системам язык запросов не потребуется и, следовательно, необходимость включения систем второго поколения отпадает. Несколько авторов настоящей работы беседовали со многими разработчиками САПР, интересующимися базами данных, и все они отмечали необходимость языка запросов. Рассмотрим, например, систему механического САПР, хранящую составные части какого-либо продукта, например, автомобиля. Помимо пространственной геометрии каждой детали, САПР-системе необходимо хранить набор атрибутных данных, таких как стоимость детали, цвет ее, среднее время наработки на отказ, сведения о поставщике детали и т.д. САПР-приложениям язык запросов нужен для задания произвольных запросов к атрибутным данным, например:
Насколько вырастет стоимость автомобиля, если поставщик X повысит цены на Y процентов?
Таким образом, мы приходим к выводу, что язык запросов абсолютно необходим.
Другим улучшением, внесенным системами второго поколения, стало введение понятия независимости данных. В области физической независимости данных системы второго поколения автоматически поддерживают согласованность всех путей доступа к данным, и оптимизатор запросов автоматически выбирает лучший способ выполнения любой выданной пользователем команды. Кроме того, системы второго поколения обеспечивают представления баз данных, посредством которых пользователь может быть изолирован от изменений анализируемого множества наборов, хранящихся в базе данных. Эти характеристики значительно снизили объем программной поддержки, которая должна быть обеспечена приложениями, и от них не стоит отказываться.
В принципе 3 обсуждается последняя философская посылка, от которой необходимо отталкиваться при создании СУБД третьего поколения.
Принцип 3: СУБД третьего поколения должны быть открыты для других подсистем.
Иными словами, любая СУБД, рассчитывающая на широкую сферу применения, должна быть оснащена языком четвертого поколения (4GL), разнообразными инструментами поддержки принятия решений, дружественным доступом из многих языков программирования, дружественным доступом из популярных подсистем, таких как LOTUS 1-2-3, интерфейсами с графическими бизнес-пакетами, возможностью запуска приложений из базы данных на другой машине и распределенной СУБД. Весь набор инструментов и СУБД должен эффективно функционировать на разнообразных аппаратных платформах с различными операционными системами.
Из этой посылки исходят два следствия. Во-первых, любая удачная система третьего поколения должна поддерживать большую часть перечисленного инструментария. Во-вторых, СУБД третьего поколения должны быть открытыми, то есть должны допускать реализацию доступа из дополнительных инструментов, функционирующих в различных средах. Более того, каждая система третьего поколения должна легко объединяться с другими СУБД для создания распределенных систем баз данных.
Эти принципы приводят к более детальным предложениям, о которых мы и расскажем далее.
Мы выдвигаем три группы детальных предложений, которым, по нашему мнению, должны следовать удачные образцы систем баз данных третьего поколения 90-х годов. Предложения первой группы следуют из принципа 1 и уточняют требования к управлению объектами и правилами. Во второй группе содержится набор предложений, являющихся следствием того, что системы третьего поколения должны включать в себя системы второго поколения. Наконец, в третью группу сведены предложения, исходящие из требования открытости систем третьего поколения.
Создатели СУБД не в состоянии предвидеть все виды элементов данных, которые могут потребоваться приложениям. Например, большая часть людей считает, что время измеряется в секундах и днях. Однако в приложениях по торговле облигациями все месяцы длятся 30 дней, в банках день заканчивается в 15:30, а в приложениях фондовой биржи "вчера" перескакивает через праздники и выходные. Следовательно, СУБД третьего поколения должны управлять разнообразными объектами, и мы выдвигаем 4 предложения по управлению объектами, касающиеся конструкторов типов, наследования, функций и уникальных идентификаторов.
Предложение 1.1: Система типов СУБД третьего поколения должна быть богатой и разнообразной.
Все перечисленное является желательным:
1) система абстрактных типов данных для создания новых базовых типов
2) конструктор типа массив
3) конструктор типа последовательность
4) конструктор типа запись
5) конструктор типа множество
6) функции как тип
7) конструктор типа объединение
8) рекурсивная композиция всех перечисленных выше конструкторов
Первый механизм позволяет конструировать новые базовые типы в дополнение к стандартному набору целых чисел, вещественных чисел и текстовых строк, имеющемуся в большей части систем. При помощи первого механизма можно конструировать битовые строки, точки, линии, комплексные числа и т.д. Второй механизм позволяет заводить массивы элементов данных, которые можно встретить, например, во многих научных приложениях. Обычным свойством массивов является отсутствие возможности вставить новый элемент в середину, сдвинув все последующие элементы. В некоторых приложениях (работающих, например, с текстовыми строками) такая вставка бывает необходимой, и конструктор третьего вида поддерживает подобные последовательности. Четвертый механизм позволяет группировать элементы данных в записи. Благодаря такому конструктору можно было бы, например, сформировать запись элементов данных о человеке, представляющем "старую гвардию" некоторого университета. Пятый механизм требуется для создания неупорядоченных наборов элементов данных или записей. Конструктор типа множество требуется, например, для создания набора всех представителей старой гвардии. Шестой механизм - функции (методы) - подробно рассмотривается в предложении 1.3; желательно, чтобы СУБД естественно сохраняла такие конструкции. Следующий механизм позволяет создавать элементы данных, которые могут принимать значения одного из нескольких типов. Примеры применения этого конструктора приведены в [COPE84]. Последний механизм позволяет рекурсивно комбинировать конструкторы типов для поддержки сложных объектов, обладающих внутренней структурой, например, документов, пространственных геометрических конструкций и т.д. Более того, в отличие от систем второго поколения, последний примененный конструктор типов не обязан быть конструктором множеств.
Помимо перечисленных конструкторов типов необходимо также расширить адекватными конструкциями используемый язык запросов. Рассмотрим, например, набор SALESPERSON, в котором каждый продавец характеризуется именем и месячными квотами, объединенными в массив из 12 целочисленных элементов. Хотелось бы обладать простыми средствами, позволяющими запросить имена продавцов, апрельская квота которых превысила $5000. Подобный запрос мог бы выглядеть таким образом:
select name from SALESPERSON where quota[4] > 5000
Следовательно, язык запросов должен быть расширен средствами обращения к массивам. Прототип синтаксиса для различных конструкторов типов содержится в [CARE88].
Полезность перечисленных конструкторов типов понятна клиентам СУБД, которым требуется хранить данные с достаточно богатой структурой. Более того, подобные конструкторы типов облегчат реализацию языков программирования со стабильными данными, обсуждаемых в предложении 3.2. Возможно, со временем станут желательными и дополнительные конструкторы типов. Например, системы обработки транзакций управляют очередями сообщений [BERN90]. Следовательно, может возникнуть необходимость в конструкторе, создающем очереди.
Системы второго поколения обладают лишь частью перечисленных конструкторов типов, и сторонники объектно-ориентированных баз данных (object-oriented data bases, OODB) утверждают, что для поддержки всех этих возможностей должны появиться качественно новые СУБД. Мы придерживаемся другой точки зрения по этому вопросу. Существуют прототипы, демонстрирующие, как добавлять к реляционным системам большую часть рассматриваемых конструкторов типов. Например, в [STON83] показано, как добавлять последовательности записей, [ZANI83] и [DADA86] указывают, как создавать некоторые сложные объекты, а [OSBO86, STON86] демонстрируют, как включать системы с абстрактными типами данных (АТД). Мы утверждаем, что все обсуждаемые конструкторы типов можно добавить к реляционным системам как естественное расширение и что технология этого расширения достаточно хорошо продумана.5) Более того, коммерческие реляционные системы с некоторыми из перечисленных возможностей уже начали появляться.Наше следующее предложение по управлению объектами касается наследования.
Предложение 1.2: Наследование - хорошая идея.
Об этой конструкции было сказано немало, так что будем кратки. Возможность организации типов в иерархию наследования - хорошая идея. Более того, нам кажется, что существенно множественное наследование, так что иерархия наследования должна представляться ориентированным графом. Поддержка только единичного наследования оказывается недостаточной для адекватного моделирования подавляющего большинства ситуаций. Рассмотрим, например, набор представителей типа PERSON. Пусть существуют две специализации типа PERSON - студент (STUDENT) и служащий (EMPLOYEE). Наконец, имеются студенты-служащие (STUDENT EMPLOYEE), которые должны наследовать свойства и студентов, и служащих. В каждом случае элементы данных, соответствующие набору, задаются при его определении, а прочие наследуются из родительских наборов. Диаграмма этой ситуации, требующей множественного наследования, изображена на рис. 1.
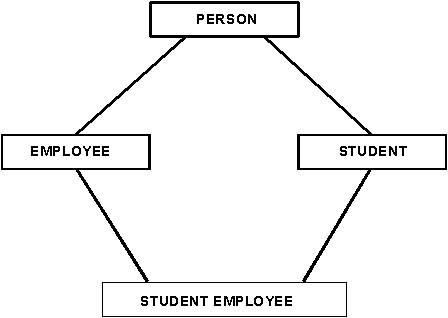
![]()
Рисунок 1.
Типичная иерархия множественного наследования.
Отметим, что, хотя в работе [ATKI89] и защищается идея наследования, множественное наследование там приводится как необязательная возможность.
Желательно также иметь наборы, для которых не задаются дополнительные поля. Например, набор TEENAGER (подросток) можно было бы определить как набор, состоящий из таких же элементов данных, что и PERSON, но обладающий ограничениями на возраст. Опять-таки, уже создавались прототипы, демонстрирующие, как добавлять эти возможности к реляционным системам, и мы ожидаем, что коммерческие реляционные системы будут развиваться в этом направлении.
Наше третье предложение касается включения функций в СУБД третьего поколения.
Предложение 1.3: Функции, в том числе процедуры и методы баз данных, и инкапсуляция - хорошие идеи.
Поддержка системами второго поколения функций и инкапсуляции ограничена. Например, в SQL над таблицами возможны только операции, осуществляемые функциями create, alter и drop. Следовательно, абстракция таблицы доступна только путем выполнения одной из перечисленных функций.
Очевидно, выгоды, предоставляемые инкапсуляцией, должны стать доступными для разработчиков приложений, чтобы те могли ассоциировать функции с пользовательскими наборами. Например, функции HIRE(EMPLOYEE), FIRE(EMPLOYEE) и RAISE-SAL(EMPLOYEE) (соответственно нанять, уволить служащего и повысить ему зарплату) должны быть ассоциированы с уже знакомым набором EMPLOYEE. Если пользователям не разрешен прямой доступ к набору EMPLOYEE, а вместо этого предоставлены упомянутые функции, вся информация о внутренней структуре объектов класса EMPLOYEE инкапсулирована внутри этих функций.
Использование инкапсуляции дает административные преимущества путем поощрения модульности и регистрации функций вместе с инкапсулируемыми данными. Если набор EMPLOYEE изменяется так, что его предыдущее содержимое нельзя определить как представление, весь код, который необходимо изменить, локализован в одном месте, следовательно, его проще модифицировать.
В защищенных или распределенных системах применение инкапсуляции часто дает выигрыш в производительности. Например, функции HIRE(EMPLOYEE) в процессе выполнения несколько раз может потребоваться доступ к базе данных. Если HIRE(EMPLOYEE) задана как функция, которая должна быть выполнена менеджером данных внутренним образом, между приложением и СУБД состоится только один цикл обмена сообщениями. С другой стороны, если функция запускается из программы пользователя, один цикл обмена сообщениями потребуется для каждого доступа. Повышение производительности благодаря переносу функций внутрь СУБД было также продемонстрировано популярным тестом Debit-Credit [ANON85].
Наконец, такие функции могут быть унаследованы и, возможно, переопределены в иерархии наследования. Следовательно, функция HIRE(EMPLOYEE) может быть автоматически применена к набору STUDENT EMPLOYEE. Если воспользоваться переопределением, функцию HIRE для набора STUDENT EMPLOYEE можно переписать. Словом, использование инкапсулированных функций ведет к повышению производительности и структурным выгодам и потому крайне желательно. Однако сделаем три замечания.
Во-первых, нам кажется, что пользователям следует писать функции на языке высокого уровня (ЯВУ) и получать доступ к базам данных при помощи непроцедурного языка доступа высокого уровня. Язык доступа может быть встроен в ЯВУ средствами препроцессора или реализован как прямое расширение ЯВУ. Другими словами, функции должны выполнять запросы, а не осуществлять навигацию путем использования вызовов интерфейсов СУБД низкого уровня. В предложении 2.1 будет обсуждаться нежелательность использования интерфейсов низкого уровня доступа к данным в программах пользователей; приведенные там соображения также применимы к конструированию функций.
Время от времени появляется необходимость в функциях, которым требуется непосредственный доступ к внутренним интерфейсам СУБД. Реализация таких функций станет нарушением сформулированной выше заповеди, гласящей, что получать доступ к базе данных следует исключительно при помощи языка запросов. Пример такой функции приведен в [STON90]. Следовательно, прямой доступ к внутренностям системы должен стать допустимым, но крайне нежелательным способом написания функций.
Второй комментарий касается понятия непрозрачных типов. Некоторые энтузиасты идеи объектно-ориентированных баз данных утверждают, что должен быть только один способ, с помощью которого пользователь может получить доступ к набору - выполнение одной из функций, применимых к набору. Например, единственным способом получения доступа к набору EMPLOYEE был бы вызов функции типа HIRE(EMPLOYEE). Такое ограничение игнорирует потребности языка запросов, среде выполнения которого требуется непосредственный доступ к каждому элементу данных. Рассмотрим такой пример:
select * from EMPLOYEE where salary > 1000
Для обработки этого запроса среде выполнения необходим непосредственный доступ к элементам данных salary, а также все вспомогательные пути доступа (индексы) к ним. Таким образом, мы считаем, что необходим механизм, делающий типы прозрачными, чтобы к элементам данных этих типов можно было получить доступ через язык запросов. Возможно, этого можно достичь при помощи автоматически определяемой "функции доступа" к каждому элементу данных или еще каким-то способом. Очевидно, необходима система авторизации для контроля за доступом к базе данных, выполняемым посредством языка запросов.6)
Последний комментарий касается коммерческого рынка. Все крупнейшие поставщики СУБД второго поколения уже поддерживают функции, написанные на ЯВУ (обычно на поддерживаемом поставщиком 4GL), которые могут производить обращения к СУБД в терминах SQL. Более того, эти функции могут быть использованы для инкапсуляции доступа к данным, которыми они управляют. Таким образом, функции, хранимые в базе данных и содержащие вызовы СУБД на языке запросов, уже получили довольно широкое распространение на рынке. Поставщикам коммерческих реляционных систем осталось поработать над поддержкой наследования функций. Опять-таки, уже создано несколько прототипов, демонстрирующих, что наследование можно реализовать как довольно прямое и естественное расширение реляционных СУБД. И вновь нам видится прямой путь, по которому современные реляционные системы могут двигаться к воплощению в жизнь нашего предложения.
Наше последнее предложение по управлению объектами касается автоматического задания уникальных идентификаторов.
Предложение 1.4: Уникальные идентификаторы (UID) записей должны задаваться СУБД только в том случае, когда недоступен определенный пользователем первичный ключ.
Системами второго поколения поддерживается понятие первичного ключа - заданного пользователем уникального идентификатора. Если у набора существует первичный ключ, который заведомо не изменится (например, номер социального обеспечения, регистрационный номер студента, номер служащего), то необходимости в дополнительных, присвоенных системой уникальных идентификаторах не возникает. Неизменный первичный ключ лучше присвоенного системой UID еще и потому, что обозначает нечто естественное, понятное человеку. При обмене данными или отладке это может быть значительным преимуществом.
Если для набора первичный ключ недоступен, появляется необходимость в присвоенном системой уникальном идентификаторе. Так как SQL поддерживает обновление с помощью курсора, системы второго поколения должны быть в состоянии обновить последнюю выбранную запись, а это возможно только при условии, что ее можно уникально идентифицировать. Если нет первичных ключей, по которым можно провести идентификацию, система должна включить дополнительный IUD. Несколько систем второго поколения уже следуют этому предложению.
Более того, как будет показано при обсуждении предложения 2.3, некоторые наборы, например, снимки, не обязательно обладают системно заданными UID, так что построение систем с принудительной уникальной идентификацией, вероятнее всего, окажется нежелательным. Мы завершим обсуждение принципа 1 последним предложением, касающимся понятия правила.
Предложение 1.5: Правила (триггеры, ограничения) станут одной из ключевых характеристик будущих систем. Их не следует ассоциировать с определенными функциями или наборами. Исследователи OODB обычно игнорировали необходимость правил, несмотря на то, что именно в языках программирования, использующих концепцию объекта, впервые появились активные значения данных и демоны. На вопрос о правилах OODB-энтузиасты отвечали либо молчанием, либо предложением внедрять их путем включения кода для их поддержки в одну или несколько функций, работающих с набором. Например, для внедрения правила о том, что любой служащий должен зарабатывать меньше, чем менеджер, потребуется вставить соответствующий этому ограничению код в две функции - HIRE(EMPLOYEE) и RAISE-SAL(EMPLOYEE).
При ассоциировании правил с функциями возникают две фундаментальные проблемы. Во-первых, при добавлении новой функции, например, PENSION-CHANGE(EMPLOYEE), изменяющей размеры пенсии, необходимо или проследить, чтобы был вызван метод RAISE-SAL(EMPLOYEE), или включить в новую функцию код для поддержки правила. Нельзя гарантировать, что программист не забудет это сделать, а, следовательно, нельзя гарантировать поддержание правил. Более того, код для поддержки правила должен быть помещен по крайней мере в две функции, HIRE(EMPLOYEE) и RAISE-SAL(EMPLOYEE). Это потребует удвоения усилий и сильно затруднит изменение правила.
Рассмотрим следующее правило:
Если изменяется зарплата Джо, необходимо таким же образом изменить зарплату Сэма.
По схеме OODB для внедрения правила требуется добавить соответствующий код к функциям HIRE и RAISE-SAL. Предположим, что добавилось еще одно правило:
Если изменяется зарплата Сэма, необходимо таким же образом изменить зарплату Фреда.
Для внедрения этого правила понадобится добавить код к тем же функциям. К тому же второе правило связано с первым. Человеку, пишущему код для поддержки второго правила, будет нужно правильно осуществить взаимодействие двух правил, а для этого придется разбираться со всеми правилами, включенными в изменяемую функцию. Та же проблема появится при последующем удалении правил.
Наконец, возможность выдать запрос о поддерживаемых в текущий момент правилах была бы очень ценной. Если правила похоронены в функциях, простого способа реализации этой возможности нет.
С нашей точки зрения, есть только одно разумное решение; правила должны поддерживаться СУБД, но не быть привязаны ни к какой функции и ни к какому набору. Из этого положения следуют два факта. Во-первых, парадигма OODB "все выражается методами" просто не применима к правилам. Во-вторых, нельзя предоставлять непосредственный доступ к внутренним интерфейсам СУБД ниже уровня активации правил (иначе пользователи смогут обходить систему, включающую правила в нужное время).
В заключение отметим, что уже существуют продукты поставщиков систем второго поколения, отвечающие приведенному предложению. Следовательно, в вопросах, касающихся этого предложения, коммерческий реляционный рынок опередил уровень исследований OODB.
Мы уже заметили, что системы третьего поколения не должны делать шаг назад, то есть они должны вобрать в себя все возможности, предоставляемые системами второго поколения. Особого внимания заслуживают язык запросов, спецификация множеств элементов данных и независимость данных. В этот раздел включены четыре предложения, касающиеся перечисленных вопросов.
Предложение 2.1: Все программируемые доступы к базам данных должны осуществляться через непроцедурный язык доступа высокого уровня.
В OODB-литературе, как правило, недооценивается критическая важность высокоуровневых языков доступа к данным, по выразительной силе не уступающих реляционному языку запросов. Например, в [ATKI89] выдвигается предложение, что СУБД должна предоставлять возможность интерактивного доступа к данным в любой удобной форме. Мы сделаем более сильное утверждение: выразительная сила языка запросов должна присутствовать в любом интерфейсе программируемого доступа; других способов доступа к данным СУБД быть не должно. В перспективе такой сервис может быть обеспечен путем добавления конструкций языка запросов к различным языкам программирования со стабильным хранением данных (о них мы поговорим в предложении 3.2). В ближайшем будущем этот сервис может быть обеспечен путем встраивания языка запросов в обычные языки программирования.
Системы второго поколения продемонстрировали, что использование этого подхода значительно снижает расходы на сопровождение программ по сравнению с системами первого поколения. С нашей точки зрения, системы третьего поколения не должны утратить это достижение. Напротив, многие исследователи OODB утверждают, что для приложений, ради которых они разрабатывают свои системы, желательна навигация к искомым данным с использованием низкоуровневого процедурного интерфейса. В частности, им требуется интерфейс с СУБД, с помощью которого можно получать доступ к определенным записям. Один или более элементов данных записи будет иметь тип "ссылка на запись в каком-то другом наборе", обычно представляемым своего рода указателем на запись другого набора, то есть идентификатором объекта. Далее, приложение выберет один из указателей для создания новой текущей записи. Этот процесс будет продолжаться до тех пор, пока приложение не доберется до искомых данных.
Навигационная точка зрения была хорошо сформулирована Чарльзом Бахманом в лекции при получении премии Тьюринга [BACH73]. Нам кажется, что 17 лет, прошедшие с того времени, показали, что подобные интерфейсы неудобны и использовать их не следует. Далее мы обсудим лишь две из множества важных проблем, связанных с навигацией. Во-первых, когда программист осуществляет навигацию к искомым данным таким образом, он заменяет функции оптимизатора запросов написанными вручную вызовами более низкого уровня. История наглядно продемонстрировала, что хорошо написанный и хорошо настроенный оптимизатор почти во всех случаях добивается лучших результатов, чем написанные вручную вызовы. Следовательно, почти наверняка программист создаст программу с более низкой производительностью. Более того, ему придется решать гораздо более сложные задачи при написании кода для сложных низкоуровневых интерфейсов.
Однако самый веский аргумент связан с эволюцией схемы. Если изменится некоторое число индексов или данные в кластере будут реорганизованы, навигационный интерфейс не сможет автоматически приспособиться к переменам. Значит, если изменятся физические пути доступа к данным, программисту придется модифицировать программу. С другой стороны, оптимизатор запросов просто создает новый план, который оптимизируется для новой среды. Более того, при изменениях физического хранения наборов поддержка представлений, воплощенная в системах второго поколения, может быть использована для изоляции приложения от перемен. Чтобы справиться с проблемой эволюции схемы и добиться требуемой оптимизации доступа к базе данных в каждой программе, пользователю следует специфицировать множество интересующих его элементов данных путем запросов на непроцедурном языке.
Рассмотрим, однако, пользователя, просматривающего базу данных, то есть осуществляющего навигацию от одной записи к другой. Такому пользователю хочется просмотреть все записи на любом маршруте сквозь исследуемую базу данных. Более того, выбор следующего маршрута, который ему захочется исследовать, может зависеть от состава текущей записи. Понятно, что в каждый момент времени этот пользователь имеет доступ к одной записи. Наша позиция по отношению к таким пользователям проста: им следует выполнять последовательность запросов, возвращающую единственную запись, например:
select * from collection where collection.key = value
Конечно, дальнейшая оптимизация подобных запросов почти невозможна, однако при этом необходимость переделки программ в случае изменения схемы отпадает. При помощи интерфейсов низкого уровня (например, командой dereference (pointer)) такого добиться невозможно.
Более того, мы утверждаем, что наш подход приносит выигрыш в производительности по сравнению с использованием низкоуровневых интерфейсов. Это утверждение, на первый взгляд, противоречит интуиции и нуждается в объяснениях. Подавляющее большинство энтузиастов OODB считают, что указатель должен быть мягким, т.е. его значение не должно меняться, даже если элемент данных, на который он указывал, был передвинут. Эта характеристика, называемая позиционной независимостью, является желательной, так как она позволяет перемещать элементы данных, не меняя при этом структуры базы данных. Перемещения элементов данных часто неизбежны при реорганизации базы данных или восстановлении после сбоев. Таким образом, энтузиасты OODB рекомендуют использовать в качестве указателей позиционно независимые уникальные идентификаторы. Как результат для перехода по указателю необходим доступ к хэшированной или индексированной структуре уникальных идентификаторов.
В SQL-представлении, пара
(имя-отношения, ключ)
в точности является позиционно независимым уникальным идентификатором, задающим тот же хэшированный или индексированный просмотр. Все накладные расходы, связанные с синтаксисом SQL, с высокой степенью вероятности придутся на время компиляции.
Таким образом, мы утверждаем, что использование интерфейсов низкого уровня для возвращения одного элемента данных дает в лучшем случае лишь микроскопический выигрыш в производительности. С другой стороны, если возвращается несколько элементов данных, замещение запроса высокого уровня множеством вызовов низкого уровня может снизить производительность из-за расходов на организацию вызовов от приложения к СУБД.
Последнее утверждение, которое часто делают энтузиасты OODB, заключается в том, что программисты, например, САПР, хотят собственноручно осуществлять навигацию, и, следовательно, система должна поощрять ее при помощи интерфейсов низкого уровня. Мы признаем, что некоторые программисты могут предпочитать навигацию. Были такие, которые отказывались переходить с ассемблера на языки высокого уровня, были и те, кто отказывался переходить к реляционным системам - на новых системах задачи были не столь сложными, а, значит, работа не столь интересная. Эти программисты думали, что смогут работать лучше, чем компиляторы и оптимизаторы. Мы считаем, что аргументы против навигации достаточно убедительны и что некоторым программистам просто не мешает подучиться.
Таким образом, мы приходим к заключению, что все обращения к данным должны задаваться запросами в нотации непроцедурного доступа высокого уровня. В предложении 3.2 мы обсудим вопросы интеграции таких запросов с современными ЯВУ.
Перейдем теперь ко второму вопросу, в котором, на наш взгляд, также нельзя оставлять завоеванные высоты. Как уже отмечено в предложении 1.1, системы третьего поколения будут поддерживать разнообразные конструкторы типов для наборов, и наше следующее предложение касается спецификации таких наборов, особенно наборов, являющихся множествами.
Предложение 2.2: Должно быть по крайней мере два способа спецификации наборов: посредством перечисления членов и путем использования языка запросов для задания членов.
В литературе по OODB предлагается задание множеств перечислением, средствами связанного списка или массива идентификаторов членов [DEWI90]. Мы полагаем, что такая спецификация - не лучший выбор. В качестве иллюстрации рассмотрим пример:
ALUMNI (name, age, address) GROUPS (g-name, composition)
Мы имеем набор выпускников определенного университета и набор групп выпускников. У каждой группы есть имя, например, "старая гвардия", "непослушные дети", "переростки", и т.д.; в поле composition (состав) указаны все выпускники, являющиеся членами группы. Конечно, можно задать состав как массив указателей на соответствующих выпускников, однако такая спецификация окажется крайне неэффективной, так как множества окажутся довольно большими и будут значительно перекрываться. Более важно то, что когда новый человек добавляется к набору ALUMNI (выпускники), добавление его в соответствующую группу входит в обязанности прикладного программиста. Иными словами, различные множества выпускников задаются "экстенсионально", перечислением членов, и принадлежность выпускника к какому-либо множеству определяется вручную прикладным программистом.
С другой стороны, можно представлять группы и в таком виде:
GROUPS (g-name, min-age, max-age,
composition)
В этом случае состав задается "интенсионально", при помощи приведенного ниже SQL-выражения:
select * from ALUMNI where age > GROUPS.min-age and age < GROUPS.max-age
Здесь для задания каждой группы требуется один запрос, параметризованный возрастными ограничениями группы. Помимо большей компактности, этот способ имеет еще одно преимущество: принадлежность множеству определяется автоматически. Таким образом, если в базу данных будет внесен еще один выпускник, автоматически он будет помещен в соответствующие множества. Можно гарантировать, что созданные таким образом множества будут семантически согласованы.
Помимо гарантированной согласованности, автоматически заданные множества обладают еще одним достоинством: они часто обеспечивают более высокую производительность, чем множества, заданные вручную. Предположим, пользователь выполняет такой запрос:
select g-name from GROUPS where composition.name = "Bill"
Этот запрос выявляет группы, членом которых является Билл. Здесь используется "вложенная точечная нотация" обращения к элементам множества, получившая распространение благодаря языку баз данных GEM [ZANI83]. Если состав задается массивом указателей, оптимизатор запросов может последовательно просматривать все записи GROUPS, и, переходя к каждому указателю, искать Билла. Оптимизатор запросов также может сначала узнать идентификатор Билла, а затем просматривать все поля композиции в поисках этого идентификатора. С другой стороны, если используется интенсиональное представление, приведенный запрос может быть преобразован оптимизатором следующим образом:
select g-name from GROUPS, ALUMNI where ALUMNI.name = "Bill" and ALUMNI.age > GROUPS.min-age and ALUMNI.age < GROUPS.max-age
Если существует индексация GROUPS.min-age или GROUPS.max-age и ALUMNI.name, такой запрос по производительности значительно превзойдет реализации первых двух планов обработки запросов.
Словом, есть по меньшей мере два способа задания наборов, таких как множества, массивы, последовательности и т.д. Их можно определять "экстенсионально" при помощи набора указателей или "интенсионально" при помощи выражения. Интенсиональная спецификация поддерживает автоматическое определение принадлежности к множеству [CODA71], что желательно для большинства приложений. Экстенсиональная спецификация предпочтительна лишь в тех случаях, когда между членами множества отсутствует структурная связь или когда автоматическое определение членства нежелательно.
Кроме того, при интенсиональной спецификации оптимизатор запросов может производить семантические преобразования. Это позволяет выбирать пути доступа, лучшие для данного запроса. Никаких ограничений, наложенных структурами указателей, не существует. Таким образом, полномочия по принятию решений по вопросам физического представления делегируются администратору базы данных, туда, где они должны находиться. Администратор может решать, какие способы доступа следует поддерживать (например, связанные списки или массивы указателей) [CARE90].
Мы считаем, что оба представления необходимы, но предпочтение должно отдаваться интенсиональному. С другой стороны, энтузиасты OODB, как правило, рекомендуют использовать лишь экстенсиональные методы. Вспомним, что в середине 70-х годов преимуществам автоматического задания множеств посвящалось немало внимания [CODD74]. Чтобы не сделать шаг назад, системы третьего поколения должны отдавать предпочтение автоматическим множествам.
Наше третье предложение в данном разделе касается представлений и их важнейшей роли в приложениях баз данных.
Предложение 2.3: Существенно наличие обновляемых представлений.
Существует очень немного статических баз данных - большая часть данных постоянно изменяется. При изменениях множества наборов может потребоваться модификация программ. Очевидно, что инкапсуляция доступа к базе данных в функции и инкапсуляция функций в один набор стала бы полезным шагом. Это позволило бы легко выявлять функции, в которые необходимо внести изменения. Однако само по себе это решение неадекватно. Если была изменена схема, на переписывание затронутых этими изменениями функций могут уйти недели или даже месяцы. В это время база данных не может просто перестать работать. Более того, при многочисленных изменениях потребуется слишком много ресурсов.
Гораздо лучшим подходом является поддержка виртуальных наборов (представлений). Системы второго поколения стали продвижением вперед по сравнению с системами первого поколения, в частности потому, что поддерживали некоторые возможности в данной области. К сожалению, обновление реляционных представлений часто оказывается невозможным. Следовательно, если пользователь осуществляет модификацию схемы и определяет существовавшие ранее наборы как представления, прикладные программы могут продолжить работать, а могут и остановиться. Системы третьего поколения должны демонстрировать лучшее поведение при обновлении представлений.
Традиционным способом поддержки обновления представлений является механизм преобразований команд [STON75]. Чтобы в процессе обновления представления не было неоднозначности, при определении снимка должна быть предоставлена дополнительная семантическая информация. Один из подходов заключается в требовании непрозрачности каждого набора, который позднее может стать представлением. В этом случае существует группа функций, посредством которых осуществляется весь доступ к набору [ROWE79], и автор определения представления должен вносить необходимые изменения в каждую из этих функций. Это повлечет за собой значительные расходы на сопровождение программ, а также не позволит выполнять обновление с помощью языка запросов. В качестве альтернативы такому подходу можно выдвинуть подходящую систему правил [STON90B]. Преимущество второго подхода заключается в том, что для обеспечения семантики обновления снимка требуется задать только одно (или несколько) правил. Это куда проще, чем внесение изменений в набор функций.
Заметим, что элементы виртуального набора не обязаны иметь уникальный идентификатор, так как физически их не существует. Следовательно, вряд ли можно требовать, чтобы каждая запись в наборе обладала уникальным идентификатором, как это делается во многих существующих прототипах OODB.
Наше последнее предложение во втором разделе заключается в том, что нельзя отказываться от независимости данных, то есть необходимо, чтобы все физические детали были спрятаны от прикладного программиста.
Предложение 2.4: Показатели производительности не имеют почти ничего общего с моделями данных и не должны в них проявляться.
Вообще, основными параметрами, по которым оценивается производительность работы с использованием как SQL, так и спецификаций более низкого уровня, являются:
Эти вопросы не имеют ничего общего с моделью данных или с использованием языков высокого уровня типа SQL вместо навигационного интерфейса низкого уровня. Например, тактика кластеризации связанных объектов представляется как важная черта OODB. Однако эта тактика использовалась в системах баз данных уже многие годы, например, являлась основным средством в большинстве методов доступа IMS. Следовательно, кластеризация является вопросом физического представления и не имеет ничего общего с моделью данных СУБД. Аналогично с моделью данных не связаны решения о том, должна ли система строить индексы для уникальных идентификаторов и следует ли ей буферизовать записи базы данных на клиентской машине или даже в пользовательском пространстве прикладной программы.
Мы беседовали со многими программистами, занимающимися нетрадиционными задачами, например, САПР, и убедились, что они нуждаются в СУБД, которая поддерживала бы их приложения, оптимизированные для инженерной среды. Для того чтобы добавление линии к инженерному чертежу занимало доли секунды, может потребоваться следующее:
Все это - вопросы производительности среды "рабочая станция/сервер", и они не имеют никакого отношения к модели данных, а также к наличию или отсутствию навигационного интерфейса.
При известном потоке запросов к базе данных следует пытаться достичь максимальной производительности. Действенность конкретных методов зависит от специфики приложений. Эти методы пригодны для любой системы баз данных.
До сих пор мы обсуждали характеристики СУБД третьего поколения. Теперь обратим внимание на прикладной программный интерфейс (Applications Programing Interface - API), посредством которого программа пользователя будет общаться с СУБД. В нашем первом предложении говорится об очевидной вещи.
Предложение 3.1: СУБД третьего поколения должны быть доступны из различных ЯВУ.
Некоторые разработчики систем утверждают, что СУБД должна быть тесно привязана к определенному языку программирования. Например, они говорят, что функция должна возвращать один и тот же результат независимо от того, была ли она выполнена в программе пользователя для временных данных или внутри СУБД для стабильных данных. Этого можно достичь только в том случае, если модель выполнения СУБД идентична модели выполнения конкретного языка программирования. Нам кажется, что это неверный подход.
Во-первых, невозможно договориться, какой именно ЯВУ использовать. Приложения кодируются и будут кодироваться на различных ЯВУ, и на горизонте пока не видно языка программирования Esperanto. Отсюда следует необходимость в многоязычной СУБД.
Однако есть еще одна причина, по которой открытая СУБД должна быть многоязычной. СУБД должна предоставлять доступ для различных внешних прикладных подсистем, например, Lotus 1-2-3. Такие подсистемы будут кодироваться на различных языках программирования - вот еще один аргумент в пользу многоязычности.
В результате СУБД третьего поколения будут доступны для программ, написанных на различных языках. Отсюда однозначно следует, что система типов ЯВУ не обязательно будет совпадать с системой типов СУБД. Итак, мы приходим к предложению:
Предложение 3.2: Язык "X с поддержкой стабильных данных" (для различных X) - хорошая идея. Языки будут поддерживаться над единой СУБД благодаря расширениям компилятора и (более или менее) сложной системе времени выполнения.
В интерфейсах систем второго поколения с языками программирования препроцессор использовался отчасти потому, что на ранней стадии разработчики СУБД не сотрудничали с разработчиками компиляторов. Более того, у сохранения независимости языка СУБД от языков программирования есть свои преимущества (например, СУБД и языки программирования можно независимо расширять и тестировать). Однако получавшиеся интерфейсы не отличались дружественностью и уже в 1977 году были охарактеризованы как "попытки приклеить яблоко к блину". Поставщики обычно концентрировали свои усилия на создании элегантного интерфейса между своими языками четвертого поколения и сервисами баз данных. Очевидно, что не менее элегантные интерфейсы можно создать и для универсальных языков программирования.
Во-первых, очень важно установить более точное соответствие между системами типов (этому будет способствовать внедрение предложения 1.1). Именно в этом состоит основная проблема современных реализаций встроенного SQL, а не в синтаксиса SQL. Во-вторых, было бы хорошо предоставить возможность сделать любую переменную в программе пользователя стабильной. Значения стабильных переменных не утрачиваются даже после окончания работы программы. В последнее время проявляется большая заинтересованность в подобных интерфейсах [LISK82, BUNE86].
Для достижения хорошей производительности "X с поддержкой стабильных данных" должен поддерживать кэш элементов данных и записей в адресном пространстве программы и аккуратно управлять содержимым этого кэша, используя некоторый алгоритм замещения. Пусть некоторый пользователь определил элемент данных как стабильный, а затем увеличивал его 100 раз. Благодаря наличию кэша эти изменения потребуют всего несколько микросекунд. В противном случае потребовалось бы 100 обращений к СУБД через защищенную границу, и каждый вызов отнял бы миллисекунды. Следовательно, наличие кэша в пространстве пользователя приведет к повышению производительности в 100 - 1000 раз для программ с высокой степенью локальности ссылок на стабильные данные. Таким образом, система времени выполнения сначала должна проверить, есть ли сохраняемый элемент в кэше, а если нет, поместить его туда. Более того, система времени выполнения должна моделировать типы, присутствующие в "X с поддержкой стабильных данных", но отсутствующие в СУБД.
Как отмечалось ранее, функции должны кодироваться путем включения вызовов к СУБД, выраженных на языке запросов. Следовательно, и для "X с поддержкой стабильных данных" также требуются средства выражения на языке запросов. Такие запросы могут быть выражены в нотации, соответствующей ЯВУ, как показывает система ODE применительно к C++ [AGRA89]. Системы времени выполнения ЯВУ должны принимать и обрабатывать такие запросы и доставлять результаты обратно в программу.
Подобные системы поддержки времени выполнения будет более (или менее) трудно построить в зависимости от конкретного ЯВУ (при этом поднимаются вопросы числа типов, которые необходимо моделировать, и степени различия языков запросов СУБД и ЯВУ). Подходящей является система времени выполнения, обеспечивающая интерфейс с СУБД для множества ЯВУ. Один из нас на основе подобного подхода успешно построил CLOS с поддержкой стабильных данных над POSTGRES [ROWE90].
Будет создано множество разнообразных "X с поддержкой стабильных данных". Для каждого из них потребуются свои модификации компилятора и системы времени выполнения. Все системы времени выполнения будут подключены к общей СУБД. Очевиден вопрос "Как выражать запросы к этой общей СУБД?". Ответ дается в нашем следующем предложении.
Предложение 3.3: Хорошо это или плохо, но SQL становится интергалактическим языком данных.
На сегодня SQL - универсальный способ выражения запросов. При создании первых коммерческих объектно-ориентированных баз данных этот факт не учитывался, и потом пришлось встраивать в продукты запросные системы на основе запросов SQL. К сожалению, многие продукты не дожили до окончания этой работы. Хотя перед SQL и стоит множество мелких проблем [DATE84], он необходим для коммерческой жизнеспособности. Любая компания-производитель объектно-ориентированных баз данных, желающая, чтобы ее продукт оказывал влияние на рынок, должна понять, что покупатели голосуют своими долларами за SQL. Более того, SQL является разумной кандидатурой для новых функций, предлагаемых в этой работе; прототипы синтаксиса для реализации некоторых новых возможностей исследованы в [BEEC88, ANSI89]. Конечно, для определенных приложений и ЯВУ могут оказаться адекватными и другие языки запросов.
Наше последнее предложение касается архитектуры, которой необходимо следовать, когда прикладная программа функционирует на одном компьютере, а СУБД находится на другом, серверном компьютере. Так как команды СУБД будут кодироваться с привлечением некоторой версии SQL, можно передавать SQL-запросы и получать искомые записи и/или сообщения о выполнении. Более того, консорциум поставщиков инструментов и СУБД (SQL Access Group) активно работает над определением и созданием прототипов основанных на SQL и средств удаленного доступа к данным. Такие средства обеспечат интероперабельность инструментальных средств и СУБД, базирующихся на языке SQL. Альтернативой является обмен сообщениями между клиентом и сервером при помощи интерфейса более низкого уровня.
В нашем последнем предложении обсуждается этот вопрос.
Предложение 3.4: Запросы и ответы на них должны образовывать нижний уровень коммуникаций между клиентом и сервером.
В средах, в которых пользователь сидит за рабочей станцией и взаимодействует с данными на удаленном сервере, встает вопрос о протоколах взаимодействия рабочей станции и сервера. Энтузиасты OODB обсуждают, должны ли посылаться запросы на единичные записи, единичные страницы или должен использоваться иной механизм. Наша точка зрения крайне проста: выражения на языке запросов должны образовывать нижний уровень коммуникаций. Конечно, если набор запросов можно упаковать в функцию, пользователь может использовать удаленный вызов для выполнения функции на сервере. Эта возможность желательна, так как она позволяет обойтись менее, чем одним сообщением на запрос.
Если используются спецификации низкого уровня, такие как передача страницы или записи, то специфицировать протокол принципиально труднее, так как возрастает число состояний; мешает и машинная зависимость. Более того, на нижнем уровне любой интерфейс, отличный от SQL-интерфейса, приведет к проигрышу в производительности [HAGM86, TAND88]. Следовательно, удаленные вызовы процедур и SQL-запросы обеспечивают адекватный уровень технологии интерфейсов.
Есть много вопросов, по которым мы соглашаемся и с энтузиастами OODB[ATKI89]. Среди них выделим выгодность использования богатой системы типов, функций, наследования и инкапсуляции. Однако во многих областях мы придерживаемся противоположных мнений. Во-первых, нам кажется, что работа [ATKI89] слишком узко сфокусирована на вопросах управления объектами. Мы, наоборот, обращаемся к более широкому кругу вопросов обеспечения решений, поддерживающих управление данными, правилами и объектами, снабженных полным набором инструментов, включающем интеграцию СУБД и языка запросов в многоязычную среду. В связи с этим нам кажется, что предлагаемые многими энтузиастами OODB одноязычные системы, не поддерживающие SQL, привлекательны лишь для довольно узкого рынка.
Во-вторых, представляется, что доступ к СУБД должен осуществляться при помощи языка запросов, и почти 20 лет истории подтверждают правильность такой точки зрения. Физической навигации, выполняемой программами пользователей или происходящей внутри функций, следует избегать. В-третьих, необходимо всячески поощрять использование автоматических наборов, так как они предоставляют массу преимуществ по сравнению с явно поддерживаемыми наборами. В-четвертых, свойство стабильности данных может быть добавлено ко многим языкам программирования. Так как не существует языка программирования, аналогичного эсперанто, этого следует достигать путем изменения компилятора и написания специфичной для языка системы времени выполнения, взаимодействующей с единой СУБД. Таким образом, языки программирования с поддержкой стабильных данных мало связаны с моделями данных. В-пятых, уникальные идентификаторы должны задаваться либо пользователем, либо системой (здесь мы вступаем в противоречие с одним из принципов из работы [ATKI89]).
Основной вопрос, по которому мы расходимся во мнениях с большей частью сообщества OODB, - возможность естественной эволюции современных реляционных систем к системам, поддерживающим возможности, обсуждаемые в данной работе. Мы верим в такую возможность. Продукты агрессивных поставщиков реляционных систем уже удовлетворяют принципам 1, 2 и 3 и обеспечивают хорошую поддержку предложений 1.3, 1.4, 1.5, 2.1, 2.3, 2.4, 3.1, 3.3 и 3.4. Для превращения в СУБД третьего поколения в эти продукты осталось добавить наследование и дополнительные конструкторы типов и внедрить языки программирования с поддержкой стабильных данных. Существуют прототипы систем, указывающие пути включения и этих средств.
С другой стороны, современные системы, провозглашаемые объектно-ориентированными, обычно не соответствуют нашим принципам и поддерживают лишь предложения 1.1 (частично), 1.2, 1.3 и 3.2. Для превращения в подлинные СУБД третьего поколения таким системам не хватает языка запросов и оптимизатора запросов, системы правил, поддержки SQL в архитектуре клиент/сервер, поддержки представлений и языков программирования со стабильными данными. Кроме того, в них должны быть отменены любые жесткие требования наличия уникальных идентификаторов и прекращено поощрение навигации. Более того, в них необходимо построить языки четвертого поколения, внедрить поддержку распределенных баз данных и осуществить настройку системы для эффективного управления данными.
Конечно, воплотить наши предложения непросто - придется столкнуться с многими проблемами. Создание языка с поддержкой стабильных данных для разнообразных ЯВУ - труднейшая задача. Другую проблему представляет включение в такие языки приемлемых конструкций языка запросов. Далее, логическое и физическое проектирование баз данных для современных реляционных систем считается непростой задачей, а с внедрением более богатой системы типов и правил она еще более усложнится. Для помощи пользователю здесь потребуются методологии и инструменты проектирования баз данных. Серьезную трудность представляет оптимизация выполнения правил. Кроме того, для успеха новых технологий крайне важна визуализация и отладка ориентированных на правила приложений. Мы призываем сообщество исследователей обратить внимание на эти вопросы.
2) Во избежание путаницы при обсуждении реляционных и прочих систем в этой работе используются нейтральные термины. Таким образом, элемент данных мы определяем как атомарное значение данных, хранящихся в базе. Каждый элемент данных имеет некоторый тип данных (для краткости просто тип); элементы данных можно объединять в записи - группы из одного или нескольких именованных элементов данных. Наконец, набором называется именованная группа записей, причем количество и типы элементов данных в каждой из них одинаковы.
3) DB2, INGRES, NON-STOP SQL, ORACLE и Rdb/VMS - торговые марки соответственно IBM, INGRES Corporation, Tandem, ORACLE Corporation и Digital Equipment Corporation.
5) Можно, конечно же, утверждать, что реляционная система со всеми этими расширениями уже не может называться реляционной, но дело не в этом. Дело в том, что такие расширения возможны и совершенно естественны.
6) Этот комментарий отражает давний спор между сторонниками инкапсуляции данных и людьми, которые считают необходимой прозрачность данных при интерактивном доступе. Нужно отметить, что полного согласия нет ни в лагере сторонников направления третьего поколения БД, ни в лагере ООБД. Мне лично в обоих лагерях ближе сторонники инкапсуляции. - Прим. научн. ред.
.gif) |