| КНИГА |
26.03.01 |
Консалтинг при автоматизации предприятий: подходы, методы, средства
ДИАГРАММЫ ПОТОКОВ ДАННЫХ
Диаграммы потоков данных (DFD) являются основным средством моделирования функциональных требований проектируемой системы. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств - продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Диаграммы потоков данных известны очень давно. В фольклоре упоминается следующий пример использования DFD для реорганизации переполненного клерками офиса, относящийся к 20-м годам. Осуществлявший реорганизацию консультант обозначил кружком каждого клерка, а стрелкой - каждый документ, передаваемый между ними. Используя такую диаграмму, он предложил схему реорганизации, в соответствии с которой двое клерков, обменивающиеся множеством документов, были посажены рядом, а клерки с малым взаимодействием были посажены на большом расстоянии. Так родилась первая модель, представляющая собой потоковую диаграмму - предвестника DFD.
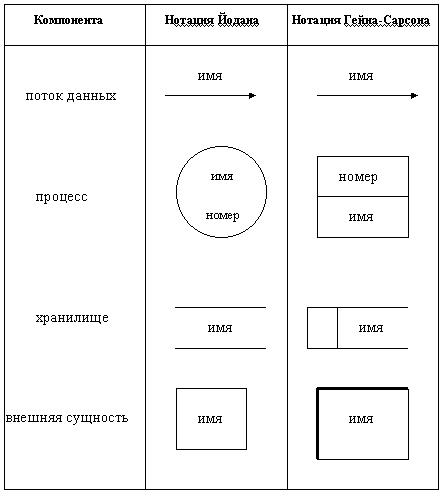
Для изображения DFD традиционно используются две различные нотации: Йодана (Yourdon) и Гейна-Сарсона (Gane-Sarson). Далее при построении примеров будет использоваться нотация Йодана, все исключения будут предварительно оговариваться.
Основные символы DFD изображены на рис.2.1. Опишем их назначение. На диаграммах функциональные требования представляются с помощью процессов и хранилищ, связанных потоками данных.
ПОТОКИ ДАННЫХ являются механизмами, использующимися для моделирования передачи информации (или даже физических компонент) из одной части системы в другую. Важность этого объекта очевидна: он дает название целому инструменту. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации.
Рис. 2.1. Основные символы диаграммы потоков данных
Иногда информация может двигаться в одном направлении, обрабатываться и возвращаться назад в ее источник. Такая ситуация может моделироваться либо двумя различными потоками, либо одним - двунаправленным.
Назначение ПРОЦЕССА состоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым именем процесса. Это имя должно содержать глагол в неопределенной форме с последующим дополнением (например, ВЫЧИСЛИТЬ МАКСИМАЛЬНУЮ ВЫСОТУ). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса процесса во всей модели.
ХРАНИЛИЩЕ (НАКОПИТЕЛЬ) ДАННЫХ позволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Фактически хранилище представляет "срезы" потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда поток данных входит или выходит в/из хранилища, и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме.
ВНЕШНЯЯ СУЩНОСТЬ (или ТЕРМИНАТОР) представляет сущность вне контекста системы, являющуюся источником или приемником системных данных. Ее имя должно содержать существительное, например, СКЛАД ТОВАРОВ. Предполагается, что объекты, представленные такими узлами, не должны участвовать ни в какой обработке.
Декомпозиция DFD осуществляется на основе процессов: каждый процесс может раскрываться с помощью DFD нижнего уровня.
Важную специфическую роль в модели играет специальный вид DFD - контекстная диаграмма, моделирующая систему наиболее общим образом. Контекстная диаграмма отражает интерфейс системы с внешним миром, а именно, информационные потоки между системой и внешними сущностями, с которыми она должна быть связана. Она идентифицирует эти внешние сущности, а также, как правило, единственный процесс, отражающий главную цель или природу системы насколько это возможно. И хотя контекстная диаграмма выглядит тривиальной, несомненная ее полезность заключается в том, что она устанавливает границы анализируемой системы. Каждый проект должен иметь ровно одну контекстную диаграмму, при этом нет необходимости в нумерации единственного ее процесса.
DFD первого уровня строится как декомпозиция процесса, который присутствует на контекстной диаграмме.
Построенная диаграмма первого уровня также имеет множество процессов, которые в свою очередь могут быть декомпозированы в DFD нижнего уровня. Таким образом строится иерархия DFD с контекстной диаграммой в корне дерева. Этот процесс декомпозиции продолжается до тех пор, пока процессы могут быть эффективно описаны с помощью коротких (до одной страницы) миниспецификаций обработки (спецификаций процессов).
При таком построении иерархии DFD каждый процесс более низкого уровня необходимо соотнести с процессом верхнего уровня. Обычно для этой цели используются структурированные номера процессов. Так, например, если мы детализируем процесс номер 2 на диаграмме первого уровня, раскрывая его с помощью DFD, содержащей три процесса, то их номера будут иметь следующий вид: 2.1, 2.2 и 2.3. При необходимости можно перейти на следующий уровень, т.е. для процесса 2.2 получим 2.2.1, 2.2.2. и т.д.
Индивидуальные данные в системе часто являются независимыми. Однако иногда необходимо иметь дело с несколькими независимыми данными одновременно. Например, в системе имеются потоки ЯБЛОКИ, АПЕЛЬСИНЫ и ГРУШИ. Эти потоки могут быть сгруппированы с помощью введения нового потока ФРУКТЫ. Для этого необходимо определить формально поток ФРУКТЫ как состоящий из нескольких элементов-потомков. Такое определение задается с помощью формы Бэкуса-Наура (БНФ) в словаре данных (см. главу 3). В свою очередь поток ФРУКТЫ сам может содержаться в потоке-предке ЕДА вместе с потоками ОВОЩИ, МЯСО и др. Такие потоки, объдиняющие несколько потоков, получили название групповых.
Обратная операция, расщепление потоков на подпотоки, осуществляется с использованием группового узла (рис. 2.2), позволяющего расщепить поток на любое число подпотоков. При расщеплении также необходимо формально определить подпотоки в словаре данных (с помощью БНФ).
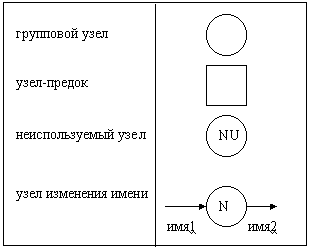
Рис 2.2. Расширения диаграммы потоков данных
Аналогичным образом осуществляется и декомпозиция потоков через границы диаграмм, позволяющая упростить детализирующую DFD. Пусть имеется поток ФРУКТЫ, входящий в детализируемый процесс. На детализирующей этот процесс диаграмме потока ФРУКТЫ может не быть вовсе, но вместо него могут быть потоки ЯБЛОКИ и АПЕЛЬСИНЫ (как будто бы они переданы из детализируемого процесса). В этом случае должно существовать БНФ-определение потока ФРУКТЫ, состоящего из подпотоков ЯБЛОКИ и АПЕЛЬСИНЫ, для целей балансирования.
Применение этих операций над данными позволяет обеспечить структуризацию данных, увеличивает наглядность и читабельность диаграмм.
Для обеспечения декомпозиции данных и некоторых других сервисных возможностей к DFD добавляются следующие типы объектов:
Главная цель построения иерархического множества DFD заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями: