| КНИГА |
15.05.01 |
Разработка ERD включает следующие основные этапы:
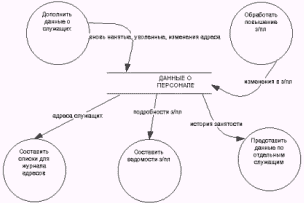
Этап 1 является определяющим при построении модели, его исходной информацией служит содержимое хранилищ данных, определяемое входящими и выходящими в/из него потоками данных. На рис. 5.7 приведен фрагмент диаграммы потоков данных, моделирующей деятельность бухгалтерии предприятия. Его единственное хранилище ДАННЫЕ О ПЕРСОНАЛЕ должно содержать информацию о всех сотрудниках: их имена, адреса, должности, оклады и т.п.
Рис. 5.7. Деятельность бухгалтерии
Первоначально осуществляется анализ хранилища, включающий сравнение содержимого входных и выходных потоков и создание на основе этого сравнения варианта схемы хранилища. Перечислим структуры данных, содержащиеся во входных и выходных потоках:
Сравнивая входные и выходные структуры, отметим следующие моменты:
С учетом этих моментов первый вариант схемы может выглядеть следующим образом:
На следующем шаге осуществляется упрощение схемы за счет устранения избыточности. Действительно, ТЕКУЩАЯ_З/ПЛ всегда является последней записью в ИСТОРИИ_З/ПЛ, а ДАТА_НАЙМА содержится в разделах ИСТОРИЯ_З/ПЛ и ИСТОРИЯ_КАРЬЕРЫ. Кроме того, несколько дат в последних разделах одни и те же, поэтому целесообразно создать на их основе структуру ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ и вводить в нее данные при изменении ДОЛЖНОСТИ и/или З/ПЛ.
Следующий шаг - упрощение схемы при помощи нормализации (удаления повторяющихся групп). Единственным способом нормализации является расщепление данной схемы на две, являющиеся более простыми. Первая схема содержит ФАМИЛИЮ и АДРЕС (которые, как правило, не меняются), вторая - каждое изменение З/ПЛ и ДОЛЖНОСТИ. Кроме того, каждая схема должна содержать ТАБ_НОМЕР - единственный элемент данных, уникально идентифицирующий каждого сотрудника.
Для идентификации сущностей осталось определить ключевые атрибуты. Для первой схемы ключевым атрибутом является ТАБ_НОМЕР, для второй - ключом является конкатенация атрибутов ТАБ_НОМЕР и ДАТА_ИЗМЕНЕНИЯ (рис.5.8), т.к. для каждого сотрудника возможно несколько записей в схеме ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ.
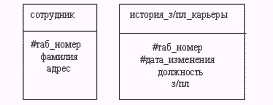
Рис. 5.8. Сущности модели
Концепции и методы нормализации были разработаны Коддом (Codd), установившим существование трех типов нормализованных схем, названных в порядке уменьшения сложности первой, второй и третьей нормальной формой (соответственно, 1НФ, 2НФ и 3НФ). Рассмотрим, как преобразовывать схемы к наиболее простой 3НФ. При этом будем представлять схемы в общепринятом виде, например, для сущностей, приведенных на рис.5.8, имеем:
Для примера построения 3НФ рассмотрим следующую схему, ключ которой выбран в предположении, что заказчик не заказывает одну и ту же книгу дважды в один и тот же день:
Согласно Кодду, любая нормализованная схема (схема без повторяющихся групп) автоматически находится в 1НФ независимо от того, насколько сложен ее ключ и какая взаимосвязь может существовать между ее элементами.
Отметим, что в последней схеме атрибуты НАЗВАНИЕ, АВТОР, ЦЕНА могут быть идентифицированы частью ключа (а именно, ISBN), тогда как атрибут КОЛИЧЕСТВО зависит от всего ключа (соответственно, полная и частичная функциональная зависимость от ключа). По определению схема находится в 2НФ если все ее неключевые атрибуты полностью функционально зависят от ключа. После избавления от частичной функциональной зависимости последняя схема будет выглядеть следующим образом:
Заметим, что возможно упростить ситуацию и дальше: атрибуты КОЛИЧЕСТВО и СУММА_ЗАКАЗА являются взаимно-зависимыми. По определению схема находится в 3НФ если она находится в 2НФ и никакой из неключевых атрибутов не является зависимым ни от какого другого неключевого атрибута. Поскольку в нашем примере атрибут СУММА_ЗАКАЗА фактически является избыточным, для получения 3НФ его можно просто удалить.
Иногда для построения 3НФ необходимо выразить зависимость между неключевыми атрибутами в виде отдельной схемы. Так для сотрудников, работающих по различным проектам, возможна следующая схема:
Очевидно, что данная схема находится в 2НФ. Однако N_ПРОЕКТА и ДАТА_ОКОНЧАНИЯ являются зависимыми атрибутами. После расщепления схемы получим 3НФ:
На практике отношения 1НФ и 2НФ имеют тенденцию возникать при попытке описать несколько реальных сущностей в одной схеме (заказ и книга, проект и сотрудник). 3НФ является наиболее простым способом представления данных, отражающим здравый смысл. Построив 3НФ, мы фактически выделяем базовые сущности предметной области.
В заключание зафиксируем алгоритм приведения ненормализованных схем в третью нормальную форму (рис. 5.9).
Этап 2 служит для выявления и определения отношений между сущностями, а также для идентификации типов отношений. На данном этапе некоторые отношения могут быть неспецифическими (n*m - многие-ко-многим). Такие отношения потребуют дальнейшей детализации на этапе 3.
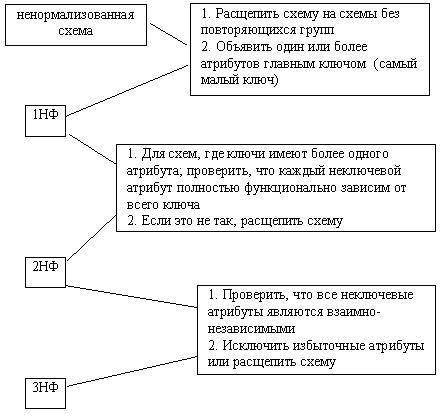
Рис. 5.9. Алгоритм приведения в 3НФ
Определение отношений включает выявление связей, для этого отношение должно быть проверено в обоих направлениях следующим образом: выбирается экземпляр одной из сущностей и определяется, сколько различных экземпляров второй сущности может быть с ним связано, и наоборот. Для примера на рис. 5.8 рассмотрим отношение между сущностями СОТРУДНИК и ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ. У отдельного сотрудника должность и/или зарплата может меняться ноль, один или много раз, порождая соответствующее число экземпляров сущности ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ. Анализируя в другом направлении, видим, что каждый экземпляр сущности ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ соответствует ровно одному конкретному сотруднику. Поэтому между этими двумя сущностями имеется отношение типа 1*n (один ко многим) со связью "один" на конце отношения у сущности СОТРУДНИК и со связью "ноль, один или много" на конце у сущности ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ.
Этап 3 предназначен для разрешения неспецифических (многие ко многим) отношений. Для этого каждое неспецифическое отношение преобразуется в два специфических отношения с введением новых (а именно, ассоциативных) сущностей. Рассмотрим пример на рис. 5.10.
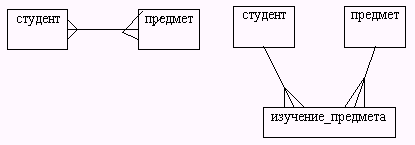
Рис. 5.10. Разрешение неспецифического отношения
Неспецифическое отношение на рис 5.10 указывает, что СТУДЕНТ может изучать много ПРЕДМЕТОВ, а ПРЕДМЕТ может изучаться многими СТУДЕНТАМИ. Однако мы не можем определить, какой СТУДЕНТ изучает какой ПРЕДМЕТ, пока не введем для разрешения этого неспецифического отношения третью (ассоциативную) сущность ИЗУЧЕНИЕ_ПРЕДМЕТА. Каждый экземпляр введенной сущности связан с одним СТУДЕНТОМ и с одним ПРЕДМЕТОМ.
Таким образом, ассоциативные сущности по своей природе являются представлениями пар реальных объектов и обычно появляются на этапе 3.