В первой части курса мы кратко рассмотрели основные требования, которым должна удовлетворять информационная система, и задачи, которые должны решаться такой системой. При этом мы постоянно подчеркивали, что строгость соблюдения требований и фиксированность набора решаемых задач во многом являются условными в зависимости от конкретных целей, для достижения которых разрабатывается прикладная информационная система. Соответственно, проектирование и разработка информационной системы может базироваться на разных архитектурных решениях.
В этой части курса приводится классификация возможных архитектур информационных систем. Мы начинаем с традиционных архитектурных решений, основанных на использовании выделенных файл-серверов или серверов баз данных. Затем рассматриваются варианты архитектур корпоративных информационных систем, базирующихся на технологии Internet (Intranet-приложения). Следующая разновидность архитектуры информационной системы основывается на концепции "склада данных" (DataWarehouse) - интегрированной информационной среды, включающей разнородные информационные ресурсы. Наконец, последняя выделяемая нами архитектура предназначена для построения глобальных распределенных информационных приложений с интеграцией информационно-вычислительных компонентов на основе объектно-ориентированного подхода.
Замечание по поводу терминологии. С терминологией в области информационных систем вообще, а русскоязычной терминологией в особенности дела обстоят неважно. Область информационных систем очень быстро развивается. Практически каждый год возникают новые технологии и архитектурные решения, для которых в маркетинговых целях придумываются оригинальные, привлекающие внимание названия, далеко не всегда точно отражающие смысл технологии и/или архитектуры. На самом деле, все подходы к организации информационных систем, рассматриваемые в этом курсе базируются на общей архитектуре "клиент-сервер". Различие состоит только в том, что делают клиенты и серверы. Тем не менее, чтобы не запутать читателя, далее мы вынуждены применять русскоязычные эквиваленты соответствующих англоязычных терминов.
Следует заметить, что как и любая классификация, наша классификация архитектур информационных систем не является абсолютно жесткой. В архитектуре любой конкретной информационной системы часто можно найти влияния нескольких общих архитектурных решений. Тем не менее, при архитектурном проектировании системы кажется полезным иметь хотя бы частично ортогонализированный архитектурный базис. В следующих частях курса мы подробно рассмотрим особенности каждой архитектуры и остановимся на методологиях и инструментально-технологических средствах, поддерживающих проектирование и разработку информационных систем в соответствующей архитектуре.
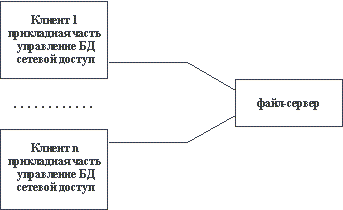
По всей видимости, организация информационных систем на основе использования выделенных файл-серверов все еще является наиболее распространенной в связи с наличием большого количества персональных компьютеров разного уровня развитости и сравнительной дешевизны связывания PC в локальные сети. Чем привлекает такая организация не очень опытных в области системного программирования разработчиков информационных систем? Скорее всего, тем, что при опоре на файл-серверные архитектуры сохраняется автономность прикладного (и большей части системного) программного обеспечения, работающего на каждой PC сети. Фактически, компоненты информационной системы, выполняемые на разных PC, взаимодействуют только за счет наличия общего хранилища файлов, которое хранится на файл-сервере. В классическом случае в каждой PC дублируются не только прикладные программы, но и средства управления базами данных. Файл-сервер представляет собой разделяемое всеми PC комплекса расширение дисковой памяти (рисунок 2.1).
Не останавливаясь подробно на имеющихся на сегодняшнем рынке перспективных инструментальных средствах разработки файл-серверных приложений и не приводя анализа тенденций развития соответствующих технологий (этому посвящается третья часть курса), мы кратко перечислим основные достоинства и недостатки файл-серверных архитектур.
Конечно, основным достоинством является простота организации. Проектировщики и разработчики информационной системы находятся в привычных и комфортных условиях IBM PC в среде MS-DOS, Windows или какого-либо облегченного варианта Windows NT. Имеются удобные и развитые средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем баз данных и/или СУБД. Но во многом эта простота является кажущейся. (Как гласит русская пословица, "Простота хуже воровства", а здесь мы, как правило, имеем простоту на основе воровства программных продуктов для PC.)
Рис. 2.1. Классическое представление информационной системы в архитектуре "файл-сервер"
Во-первых, информационной системе предстоит работать с базой данных. Следовательно, эта база данных должна быть спроектирована. Почему-то часто разработчики файл-серверных приложений считают, что по причине простоты средств управления базами данных проблемой проектирования базы данных можно пренебречь. Конечно, это неправильно. База данных есть база данных. Чем качественнее она спроектирована, тем больше шансов впоследствии эффективно использовать информационную систему. Естественно, сложность проектирования базы данных определяется объективной сложностью моделируемой предметной области. Но, собственно, из чего должно следовать, что файл-серверные приложения пригодны только в простых предметных областях?
Во-вторых, как мы неоднократно подчеркивали в первой части курса, необходимыми требованиями к базе данных информационной системы являются поддержание ее целостного состояния и гарантированная надежность хранения информации. Минимальными условиями, при соблюдении которых можно удовлетворить эти требования, являются:
В принципе, файл-серверная организация, как она показана на рисунке 2.1, не противоречит соблюдению отмеченных условий. В качестве примера системы, соблюдающей выполнение этих условий, но основанной на файл-серверной архитектуре, можно привести популярный в прошлом "сервер баз данных" Informix SE.
Длинноезамечание:
Для сохранения четкости дальнейшего изложения нам необходимо несколько уточнить терминологию. Мы недаром написали "сервер баз данных" в кавычках применительно к СУБД Informix SE. При использовании этой системы копия программного обеспечения СУБД поддерживалась для каждого инициированного пользователем сеанса работы с СУБД. Грубо говоря, для каждого пользовательского процесса, взаимодействующего с базой данных создавался служебный процесс СУБД, который выполнялся на том же процессоре, что и пользовательский процесс (т.е. на стороне клиента). Каждый из этих служебных процессов вел себя фактически так, как если бы был единственным представителем СУБД. Вся синхронизация возможной параллельной работы с базой данных производилась на уровне файлов внешней памяти, содержащих базу данных. Условимся впредь называть такие СУБД не серверами баз данных, а системами управления базами данных, основанными на файл-серверной архитектуре (СУБД-ФС).
Под истинным сервером баз данных мы будем понимать программное образование, привязанное к соответствующей базе (базам) данных, существующее, вообще говоря, независимо от существования пользовательских (клиентских) процессов и выполняемое, вообще говоря (хотя и не обязательно) на выделенной аппаратуре (мы намеренно используем не очень конкретные термины "программное образование" и "выделенная аппаратура", потому что их конкретное воплощение различается в разных серверах баз данных).
Истинные серверы баз данных существенно сложнее по организации, чем СУБД-ФС, на зато обеспечивают более тонкое и эффективное управление базами данных. Везде далее в этом курсе при употреблении термина "сервер баз данных" мы будем иметь в виду истинные серверы баз данных.
Но с другой стороны, в большинстве персональных СУБД эти условия не выполняются даже с помощью грубых приемов. В лучшем случае удается частично восполнить недостатки на уровне прикладных программ.
В третьих, интерфейс развитых серверов баз данных основан на использовании высокоуровневого языка баз данных SQL, что позволяет использовать сетевой трафик между клиентом и сервером баз данных только в полезных целях (от клиента к серверу в основном пересылаются операторы языка SQL, от сервера к клиенту - результаты выполнения операторов). В файл-серверной организации клиент работает с удаленными файлами, что вызывает существенную перегрузку трафика (поскольку СУБД-ФС работает на стороне клиента, то для выборки полезных данных в общем случае необходимо просмотреть на стороне клиента весь соответствующий файл целиком).
В целом, в файл-серверной архитектуре мы имеем "толстого" клиента и очень "тонкий" сервер в том смысле, что почти вся работа выполняется на стороне клиента, а от сервера требуется только достаточная емкость дисковой памяти (рисунок 2.2).
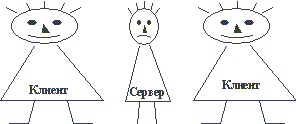
Рис. 2.2. "Толстый" клиент и "тонкий" сервер в файл-серверной архитектуре
Краткие выводы. Простое, работающее с небольшими объемами информации и рассчитанное на применение в однопользовательском режиме, файл-серверное приложение можно спроектировать, разработать и отладить очень быстро. Очень часто для небольшой компании для ведения, например, кадрового учета достаточно иметь изолированную систему, работающую на отдельно стоящем PC. Конечно, и в этом случае требуется большая аккуратность конечных пользователей (или администраторов, наличие которых в этом случае сомнительно) для надежного хранения и поддержания целостного состояния данных. Однако, в уже ненамного более сложных случаях (например, при организации информационной системы поддержки проекта, выполняемого группой) файл-серверные архитектуры становятся недостаточными.
Под клиент-серверным приложением мы будем понимать информационную систему, основанную на использовании серверов баз данных (см. длинное замечание в конце раздела 2.1). Общее представление информационной системы в архитектуре "клиент-сервер" показано на рисунке 2.3.
(Здесь опять проявляются недостатки в терминологии. Обычно, когда компания объявляет о выпуске очередного сервера баз данных, то неявно понимается, что имеется и клиентская составляющая этого продукта. Сочетание "клиентская часть сервера баз данных" кажется несколько странным, но нам придется пользоваться именно этим термином.)
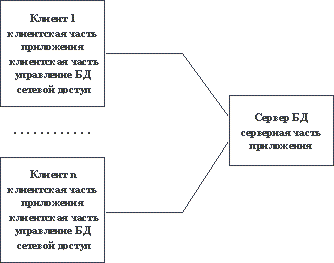
Рис. 2.3. Общее представление информационной системы в архитектуре "клиент-сервер"
Заметим, что интерфейс между клиентской частью приложения и клиентской частью сервера баз данных, как правило, основан на использовании языка SQL. Поэтому такие функции, как, например, предварительная обработка форм, предназначенных для запросов к базе данных, или формирование результирующих отчетов выполняются в коде приложения.
Наконец, клиентская часть сервера баз данных, используя средства сетевого доступа, обращается к серверу баз данных, передавая ему текст оператора языка SQL.
Здесь необходимо сделать еще два замечания.
Мы остановимся на этих вопросах более подробно в четвертой части курса.
Посмотрим теперь, что же происходит на стороне сервера баз данных. В продуктах практически всех компаний сервер получает от клиента текст оператора на языке SQL.
Как видно, в клиент-серверной организации клиенты могут являться достаточно "тонкими", а сервер должен быть "толстым" настолько, чтобы быть в состоянии удовлетворить потребности всех клиентов (рисунок 2.4).
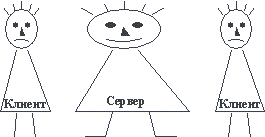
Рис. 2.4. "Тонкий" клиент и "толстый" сервер в клиент-серверной архитектуре
С другой стороны, разработчики и пользователи информационных систем, основанных на архитектуре "клиент-сервер", часто бывают неудовлетворены постоянно существующими сетевыми накладными расходами, которые следуют из потребности обращаться от клиента к серверу с каждым очередным запросом. На практике распространена ситуация, когда для эффективной работы отдельной клиентской составляющей информационной системы в действительности требуется только небольшая часть общей базы данных. Это приводит к идее поддержки локального кэша общей базы данных на стороне каждого клиента.
Фактически, концепция локального кэширования базы данных является частным случаем концепции реплицированных (или, как иногда их называют в русскоязычной литературе, тиражированных) баз данных. Как и в общем случае, для поддержки локального кэша базы данных программное обеспечение рабочих станций должно содержать компонент управления базами данных - упрощенный вариант сервера баз данных, который, например, может не обеспечивать многопользовательский режим доступа. Отдельной проблемой является обеспечение согласованности (когерентности) кэшей и общей базы данных. Здесь возможны различные решения - от автоматической поддержки согласованности за счет средств базового программного обеспечения управления базами данных до полного перекладывания этой задачи на прикладной уровень. В любом случае, клиенты становятся более толстыми при том, что сервер тоньше не делается (рисунок 2.5).

Рис. 2.5. "Потолстевший" клиент и "толстый" сервер в клиент-серверной архитектуре с поддержкой локального кэша на стороне клиентов
Сформулируем некоторые предварительные выводы. Архитектура "клиент-сервер" на первый взгляд кажется гораздо более дорогой, чем архитектура "файл-сервер". Требуется более мощная аппаратура (по крайней мере, для сервера) и существенно более развитые средства управления базами данных. Однако, это верно лишь частично. Громадным преимуществом клиент-серверной архитектуры является ее масштабируемость и вообще способность к развитию.
При проектировании информационной системы, основанной на этой архитектуре, большее внимание следует обращать на грамотность общих решений. Технические средства пилотной версии могут быть минимальными (например, в качестве аппаратной основы сервера баз данных может использоваться одна из рабочих станций). После создания пилотной версии нужно провести дополнительную исследовательскую работу, чтобы выяснить узкие места системы. Только после этого необходимо принимать решение о выборе аппаратуры сервера, которая будет использоваться на практике.
Увеличение масштабов информационной системы не порождает принципиальных проблем. Обычным решением является замена аппаратуры сервера (и, может быть, аппаратуры рабочих станций, если требуется переход к локальному кэшированию баз данных). В любом случае практически не затрагивается прикладная часть информационной системы. В идеале, которого, конечно же не бывает, информационная система продолжает нормально функционировать после смены аппаратуры.
Возникновение и внедрение в широкую практику высокоуровневых служб Всемирной Сети Сетей Internet (e-mail, ftp, telnet, Gopher, WWW и т.д.) естественным образом повлияли на технологию создания корпоративных информационных систем, породив направление, известное теперь под названием Intranet. По сути дела, информационная Intranet-система - это корпоративная система, в которой используются методы и средства Internet. Такая система может быть локальной, изолированной от остального мира Internet, или опираться на виртуальную корпоративную подсеть Internet. В последнем случае особенно важны средства защиты информации от несанкционированного доступа. Возможности и проблемы безопасных информационных Intranet-систем мы рассмотрим в пятой части курса.
Хотя в общем случае в Intranet-системе могут использоваться все возможные службы Internet, наибольшее внимание привлекает гипермедийная служба WWW (World Wide Web - Всемирная Паутина). Видимо, для этого имеются две основные причины. Во-первых, с использованием языка гипермедийной разметки документов HTML можно сравнительно просто разработать удобную для использования информационную структуру, которая в дальнейшем будет обслуживаться одним из готовых Web-серверов. Во-вторых, наличие нескольких готовых к использованию клиентских частей - браузеров, или "обходчиков" избавляет от необходимости создавать собственные интерфейсы с пользователями, предоставляя им удобные и развитые механизмы доступа к информации. В ряде случаев такая организация корпоративной информационной системы (рисунок 2.6) оказывается достаточной для удовлетворения потребностей компании.
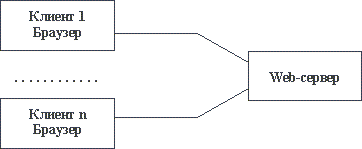
Рис. 2.6. Простая организация Intranet-системы с использованием средств WWW
Однако, при всех своих преимуществах (простота организации, удобство использования, стандартность интерфейсов и т.д.) эта схема обладает сильными ограничениями. Прежде всего, как видно из рисунка 2.6, в информационной системе отсутствует прикладная обработка данных. Все, что может пользователь, это только просмотреть информацию, поддерживаемую Web-сервером. Далее, гипертекстовые структуры трудно модифицируются. Для того, чтобы изменить наполнение Web-сервера, необходимо приостановить работу системы, внести изменения в HTML-описания и только затем продолжить нормальное функционирование. Наконец, далеко не всегда достаточен поиск информации в стиле просмотра гипертекста. Базы данных и соответствующие средства выборки данных по-прежнему часто необходимы.
На самом деле, все перечисленные трудности могут быть разрешены с использованием более развитых механизмов Web-технологии. Эти механизмы непрерывно совершенствуются, что одновременно и хорошо и плохо. Хорошо, потому что появляются новые возможности. Плохо, потому что отсутствует стандартизация.
Что касается логики приложения, то при применении Web-технологии существует возможность ее реализации на стороне Web-сервера. Для этого могут использоваться два подхода - CGI (Common Gateway Interface) и API (Application Programming Interface). Оба подхода основываются на наличии в языке HTML специальных конструкций, информирующих клиента-браузера, что ему следует послать Web-серверу специальное сообщение, при получении которого сервер должен вызвать соответствующую внешнюю процедуру, получить ее результаты и вернуть их клиенту в стандартном формате HTTP (рисунок 2.7).
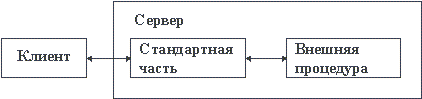
Рис. 2.7. Вызов внешней процедуры Web-сервера
Более подробно различия между подходами CGI и API мы рассмотрим в пятой части курса, а пока лишь заметим, что подход CGI является более надежным (внешняя программа выполняется в отдельном адресном пространстве), но менее эффективным, чем подход API (в этом случае внешние процедуры компонуются совместно со стандартной частью Web-сервера).
Аналогичная техника широко используется для обеспечения унифицированного доступа к базам данных в Intranet-системах. Язык HTML позволяет вставлять в гипертекстовые документы формы. Когда браузер натыкается на форму, он предлагает пользователю заполнить ее, а затем посылает серверу сообщение, содержащее введенные параметры. Как правило, к форме приписывается некоторая внешняя процедура сервера. При получении сообщения от клиента сервер вызывает эту внешнюю процедуру с передачей параметров пользователя. Понятно, что такая внешняя процедура может, в частности, играть роль шлюза между Web-сервером и сервером баз данных. В этом случае параметры должны специфицировать запрос пользователя к базе данных. В результате получается конфигурация информационной системы, схематически изображенная на рисунке 2.8.
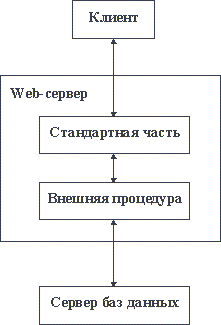
Рис. 2.8. Доступ к базе данных в Intranet-системе
Конечно, мы привели только грубую схему организации доступа к базам данных. Более детальное обсуждение содержится в пятой части курса.
На принципах использования внешних процедур основывается также возможность модификации документов, поддерживаемых Web-сервером, а также создание временных "виртуальных" HTML-страниц.
Даже начальное введение в Intranet было бы неполным, если не упомянуть про возможности языка Java. Java - это интерпретируемый объектно-ориентированный язык программирования, созданный на основе языка Си++ с удалением из него таких "опасных" средств как адресная арифметика. Мобильные коды (апплеты), полученные в результате компиляции Java-программы, могут быть привязаны в HTML-документу. В этом случае они поступают на сторону клиента вместе с документом и выполняются либо автоматически, либо по явному указанию. Апплет может быть, в частности, специализирован как шлюз к серверу баз данных (или к какому-либо другому серверу). При применении подобной техники доступа к базам данных схема организации Intranet-системы становится такой как на рисунке 2.9.
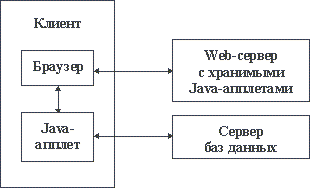
Рис. 2.9. Доступ к базе данных на стороне клиента Intranet-системы
На наш взгляд, Intranet является удобным и мощным средством разработки и использования информационных систем. Как мы уже отмечали, единственным относительным недостатком подхода можно считать постоянное изменение механизмов и естественное отсутствие стандартов. С другой стороны, если информационная система будет создана с использованием текущего уровня технологии и окажется удовлетворяющей потребностям корпорации, то никто не будет обязан что-либо менять в системе по причине появления более совершенных механизмов.
До сих пор мы рассматривали способы и возможные архитектуры информационных систем, предназначенных для оперативной обработки данных, т.е. для получения текущей информации, позволяющей решать повседневные проблемы корпорации. Однако у аналитических отделов корпорации и у высшего звена управляющего состава имеются и другие задачи: проанализировав поведение корпорации на рынке с учетом сопутствующих внешних факторов и спрогнозировав хотя бы ближайшее будущее, выработать тактику, а возможно, и стратегию корпорации. Понятно, что для решения таких задач требуются данные и прикладные программы, отличные от тех, которые используются в оперативных информационных системах. В последние несколько лет все более популярным становится подход, основанный на концепциях склада данных и системы оперативной аналитической обработки данных. Возможно, в российских условиях трудно производить долговременные прогнозы бизнес-деятельности (слишком изменчивы внешние факторы), но анализ прошлого и краткосрочные прогнозы будущего могут оказаться очень полезными.
Прежде чем перейти к обсуждению технических аспектов, коротко обсудим проблемы терминологии. Поскольку термины, связанные со складами данных не так давно появились и на английском языке, и смысл их постоянно уточняется, трудно найти правильные русскоязычные эквиваленты. На сегодняшний день "datawarehouse" разными авторами переводится на русский язык как "хранилище данных", "информационное хранилище", "склад данных". Поскольку термин "хранилище" явно перегружен (он соответствует и английским терминам "storage" и "repository"), в этом курсе мы будем использовать термин "склад данных". Еще хуже дела обстоят с термином "data mart". В четвертом номере журнала "СУБД" за 1996 г. в напечатанных подряд двух статьях авторы переводят этот термин как "витрина данных" и "секция данных" соответственно. Однако в Оксфордском толковом словаре единственным подходящем по смыслу толкованием смысла слова "mart" является "market place". Чтобы не умножать число требуемых сущностей мы будем использовать термин "рынок данных" (обсуждение этого понятия отложим до пятой части курса). Конечно, постепенно терминология будет согласована, но это произойдет только тогда, когда склады данных будут активно использоваться в России.
В этом разделе мы не будем рассматривать возможные технологические приемы реализации складов данных, а обсудим соответствующие вопросы на концептуальном уровне. Начнем с того, что главным образом различает оперативные и аналитические информационные приложения с точки зрения обеспечения требуемых данных. Замечание: речь идет о так называемых OLAP-системах (от On-Line Analitical Processing), т.е. аналитических системах, помогающих принимать бизнес-решения за счет динамически производимых анализа, моделирования и/или прогнозирования данных.
С учетом приведенных замечаний общая архитектура склада данных и системы аналитической обработки данных может выглядеть так, как показано на рисунке 2.10.
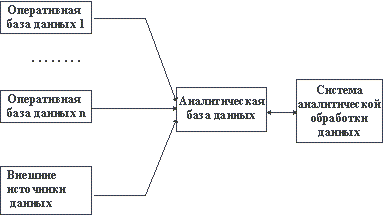
Рис. 2.10. Схематическое представление архитектуры аналитической информационной системы
В 1993 г. основоположник реляционного подхода к организации баз данных Эдвар Кодд, исходя из потребностей систем динамической аналитической обработки данных, сформулировал 12 основных требований к системам, поддерживающим аналитические базы данных. Мы приведем изложение этих требований, чтобы представить точку зрения проектировщика и разработчика системы аналитической обработки данных.
Основным выводом из материала этого раздела является то, что подход складов данных еще слишком молод, чтобы вокруг него сложился круг общепринятых понятий, терминов, технологических приемов. Тем не менее, он кажется настолько важным и перспективным, что многие компании (в том числе и ведущие производители СУБД) ведут активную работу, чтобы быть в авангарде этого направления. Существующие идеи и реализации мы рассмотрим в пятой части курса.
Нет никаких проблем, если с самого начала информационное приложение проектируется и разрабатывается в духе подхода открытых систем: все компоненты являются мобильными и интероперабельными, общее функционирование системы не зависит от конкретного местоположения компонентов, система обладает хорошими возможностями сопровождаемости и развития. К сожалению, на практике этот идеал является трудно достижимым. По разным причинам (мы перечислим некоторые из них ниже) возникают потребности в интеграции независимо и по-разному организованных информационно-вычислительных ресурсов. Видимо, ни в одной действительно серьезной распределенной информационной системе не удастся обойтись без применения некоторой технологии интеграции. К счастью, теперь существует путь решения этой проблемы, который сам лежит в русле открытых систем, - подход, предложенный крупнейшим международным консорциумом OMG (Object Management Group).
Остановимся на некоторых факторах, стимулирующих использование методов интеграции разнородных информационных ресурсов (здесь используются материалы статьи Л.А.Калиниченко и др. из журнала "СУБД" N 4, 1995 г.).
Решение проблемы интеграции неоднородных информационных ресурсов началось с попыток интеграции неоднородных баз данных. Направление интегрированных или федеративных систем неоднородных БД и мульти-БД появилось в связи с необходимостью комплексирования систем БД, основанных на разных моделях данных и управляемых разными СУБД.
Основной задачей интеграции неоднородных БД является предоставление пользователям интегрированной системы глобальной схемы БД, представленной в некоторой модели данных, и автоматическое преобразование операторов манипулирования БД глобального уровня операторы, понятные соответствующим локальным СУБД. В теоретическом плане проблемы преобразования решены, имеются реализации.
При строгой интеграции неоднородных БД локальные системы БД утрачивают свою автономность. После включения локальной БД в федеративную систему все дальнейшие действия с ней, включая администрирование, должны вестись на глобальном уровне. Поскольку пользователи часто не соглашаются утрачивать локальную автономность, желая тем не менее иметь возможность работать со всеми локальными СУБД на одном языке и формулировать запросы с одновременным указанием разных локальных БД, развивается направление мульти-БД. В системах мульти-БД не поддерживается глобальная схема интегрированной БД и применяются специальные способы именования для доступа к объектам локальных БД. Как правило, в таких системах на глобальном уровне допускается только выборка данных. Это позволяет сохранить автономность локальных БД.
Как правило, интегрировать приходится неоднородные БД, распределенные в вычислительной сети. Это в значительной степени усложняет реализацию. Дополнительно к собственным проблемам интеграции приходится решать все проблемы, присущие распределенным СУБД: управление глобальными транзакциями, сетевую оптимизацию запросов и т.д. Очень трудно добиться эффективности. Как правило, для внешнего представления интегрированных и мульти-БД используется (иногда расширенная) реляционная модель данных. В последнее время все чаще предлагается использовать объектно-ориентированные модели, но на практике пока основой является реляционная модель. Поэтому, в частности, включение в интегрированную систему локальной реляционной СУБД существенно проще и эффективнее, чем включение СУБД, основанной на другой модели данных. Основным недостатком систем интеграции неоднородных баз данных является то, что при этом не учитываются "поведенческие" аспекты компонентов прикладной системы. Легко заметить, что даже при наличии развитой интеграционной системы, большинство из указанных выше проблем не решается. Естественным развитием взглядов на информационные ресурсы является их представление в виде набора типизированных объектов, сочетающих возможности сохранения информации (своего состояния) и обработки этой информации (за счет наличия хорошо определенного множества методов, применимых к объекту). Наиболее существенный вклад в создание соответствующей технологии внес международный консорциум OMG, выпустивший ряд документов, в которых специфицируются архитектура и инструментальные средства поддержки распределенных информационных систем, интегрированных на основе общего объектно-ориентированного подхода.
В базовом документе специфицируется эталонная модель архитектуры (OMA - Object Management Architecture) распределенной информационной системы (рисунок 2.11).
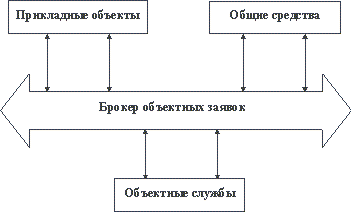
Рис. 2.11. Эталонная модель OMA
Согласованная с архитектурой OMA прикладная информационная система представляется как совокупность классов и экземпляров объектов, которые взаимодействуют при поддержке брокера объектных заявок (ORB - Object Request Broker). ORB, общие средства (Common Facilities) и объектные службы (Object Services) относятся к категории промежуточного программного обеспечения (middleware) и должны поставляться вместе. Объектные службы представляют собой набор услуг (интерфейсов и объектов), которые обеспечивают выполнение базовых функций, требуемых для реализации прикладных объектов и объектов категории "общие средства" (например, специфицированы служба именования объектов, служба долговременного хранения объектов, служба управления транзакциями и т.д.). Общие средства содержат набор классов и экземпляров объектов, поддерживающих функции, полезные в разных прикладных областях (например, средства поддержки пользовательского интерфейса, средства управления информацией и т.д.).
В основе OMA лежит базовая объектная модель COM (Core Object Model), в которой специфицированы такие понятия, как объект, операция, тип, подтипизация, наследование, интерфейс. Определены также способы согласованного расширения COM в разных объектных службах.
Интерфейсы объекта-клиента и объекта-сервера должны быть определены на специальном языке IDL (Interface Definition Language), который очень напоминает компонент спецификации класса (без реализации) языка Си++. Обращения к ORB могут быть сгенерированы статически при компиляции спецификаций IDL или выполнены динамически с использованием специфицированного в документах OMG API брокера объектных заявок. Правила построения и использования ORB определены в документе OMG CORBA (Common Object Request Broker Architecture).
В седьмой части курса мы рассмотрим более подробно все понятия, введенные в этом разделе.
Основным выводом из материала данного раздела является то, что проблемы интеграции неоднородных информационных ресурсов являются актуальными для корпораций и существуют технологии, позволяющие решать эти проблемы.
В заключение второй части курса повторим, что приведенная классификация методов и технологий не является ортогональной. В реальной жизни требуется использовать разумные сочетания технологических и архитектурных решений. Цель курса не состоит в том, чтобы выдать готовые рецепты построения информационной системы. Мы стремимся погрузить слушателей в мир информационных технологий с тем, чтобы впоследствии было проще ориентироваться в этом мире и понимать значение его сущностей.
Назад | Содержание | Вперед