| Сервер Информационных Технологий содержит море(!) аналитической информации |
Сервер поддерживается |
|---|
| Сервер Информационных Технологий содержит море(!) аналитической информации |
Сервер поддерживается |
|---|
Ключевым компонентом любой распределенной системы является файловая система. Как и в централизованных системах, в распределенной системе функцией файловой системы является хранение программ и данных и предоставление доступа к ним по мере необходимости. Файловая система поддерживается одной или более машинами, называемыми файл-серверами. Файл-серверы перехватывают запросы на чтение или запись файлов, поступающие от других машин (не серверов). Эти другие машины называются клиентами. Каждый посланный запрос проверяется и выполняется, а ответ отсылается обратно. Файл-серверы обычно содержат иерархические файловые системы, каждая из которых имеет корневой каталог и каталоги более низких уровней. Рабочая станция может подсоединять и монтировать эти файловые системы к своим локальным файловым системам. При этом монтируемые файловые системы остаются на серверах.
Важно понимать различие между файловым сервисом и файловым сервером. Файловый сервис - это описание функций, которые файловая система предлагает своим пользователям. Это описание включает имеющиеся примитивы, их параметры и функции, которые они выполняют. С точки зрения пользователей файловый сервис определяет то, с чем пользователи могут работать, но ничего не говорит о том, как все это реализовано. В сущности, файловый сервис определяет интерфейс файловой системы с клиентами.
Файловый сервер - это процесс, который выполняется на отдельной машине и помогает реализовывать файловый сервис. В системе может быть один файловый сервер или несколько, но в хорошо организованной распределенной системе пользователи не знают, как реализована файловая система. В частности, они не знают количество файловых серверов, их месторасположение и функции. Они только знают, что если процедура определена в файловом сервисе, то требуемая работа каким-то образом выполняется, и им возвращаются требуемые результаты. Более того, пользователи даже не должны знать, что файловый сервис является распределенным. В идеале он должен выглядеть также, как и в централизованной файловой системе.
Так как обычно файловый сервер - это просто пользовательский процесс (или иногда процесс ядра), выполняющийся на некоторой машине, в системе может быть несколько файловых серверов, каждый из которых предлагает различный файловый сервис. Например, в распределенной системе может быть два сервера, которые обеспечивают файловые сервисы систем UNIX и MS-DOS соответственно, и любой пользовательский процесс пользуется подходящим сервисом.
Файловый сервис в распределенных файловых системах (впрочем как и в централизованных) имеет две функционально различные части: собственно файловый сервис и сервис каталогов. Первый имеет дело с операциями над отдельными файлами, такими, как чтение, запись или добавление, а второй - с созданием каталогов и управлением ими, добавлением и удалением файлов из каталогов и т.п.
Для любого файлового сервиса, независимо от того, централизован он или распределен, самым главным является вопрос, что такое файл? Во многих системах, таких как UNIX и MS DOS, файл - это неинтерпретируемая последовательность байтов. Значение и структура информации в файле является заботой прикладных программ, операционную систему это не интересует.
В ОС мейнфреймов поддерживаются разные типы логической организации файлов, каждый с различными свойствами. Файл может быть организован как последовательность записей, и у операционной системы имеются вызовы, которые позволяют работать на уровне этих записей. Большинство современных распределенных файловых систем поддерживают определение файла как последовательности байтов, а не последовательности записей. Файл характеризуется атрибутами: именем, размером, датой создания, идентификатором владельца, адресом и другими.
Важным аспектом файловой модели является возможность модификации файла после его создания. Обычно файлы могут модифицироваться, но в некоторых распределенных системах единственными операциями с файлами являются СОЗДАТЬ и ПРОЧИТАТЬ. Такие файлы называются неизменяемыми. Для неизменяемых файлов намного легче осуществить кэширование файла и его репликацию (тиражирование), так как исключается все проблемы, связанные с обновлением всех копий файла при его изменении.
Файловый сервис может быть разделен на два типа в зависимости от того, поддерживает ли он модель загрузки-выгрузки или модель удаленного доступа. В модели загрузки-выгрузки пользователю предлагаются средства чтения или записи файла целиком. Эта модель предполагает следующую схему обработки файла: чтение файла с сервера на машину клиента, обработка файла на машине клиента и запись обновленного файла на сервер. Преимуществом этой модели является ее концептуальная простота. Кроме того, передача файла целиком очень эффективна. Главным недостатком этой модели являются высокие требования к дискам клиентов. Кроме того, неэффективно перемещать весь файл, если нужна его маленькая часть.
Другой тип файлового сервиса соответствует модели удаленного доступа, которая предполагает поддержку большого количества операций над файлами: открытие и закрытие файлов, чтение и запись частей файла, позиционирование в файле, проверка и изменение атрибутов файла и так далее. В то время как в модели загрузки-выгрузки файловый сервер обеспечивал только хранение и перемещение файлов, в данном случае вся файловая система выполняется на серверах, а не на клиентских машинах. Преимуществом такого подхода являются низкие требования к дисковому пространству на клиентских машинах, а также исключение необходимости передачи целого файла, когда нужна только его часть.
Природа сервиса каталогов не зависит от типа используемой модели файлового сервиса. В распределенных системах используются те же принципы организации каталогов, что и в централизованных, в том числе многоуровневая организация каталогов.
Принципиальной проблемой, связанной со способами именования файлов, является обеспечение прозрачности. В данном контексте прозрачность понимается в двух слабо различимых смыслах. Первый - прозрачность расположения - означает, что имена не дают возможности определить месторасположение файла. Например, имя /server1/dir1/ dir2/x говорит, что файл x расположен на сервере 1, но не указывает, где расположен этот сервер. Сервер может перемещаться по сети, а полное имя файла при этом не меняется. Следовательно, такая система обладает прозрачностью расположения.
Предположим, что файл x очень большой, а на сервере 1 мало места, предположим далее, что на сервере 2 места много. Система может захотеть переместить автоматически файл x на сервер 2. К сожалению, когда первый компонент всех имен - это имя сервера, система не может переместить файл на другой сервер автоматически, даже если каталоги dir1 и dir2 находятся на обоих серверах. Программы, имеющие встроенные строки имен файлов, не будут правильно работать в этом случае. Система, в которой файлы могут перемещаться без изменения имен, обладает свойством независимости от расположения. Распределенная система, которая включает имена серверов или машин непосредственно в имена файлов, не является независимой от расположения. Система, базирующаяся на удаленном монтировании, также не обладает этим свойством, так как в ней невозможно переместить файл из одной группы файлов в другую и продолжать после этого пользоваться старыми именами. Независимости от расположения трудно достичь, но это желаемое свойство распределенной системы.
Большинство распределенных систем используют какую-либо форму двухуровневого именования: на одном уровне файлы имеют символические имена, такие как prog.c, предназначенные для использования людьми, а на другом - внутренние, двоичные имена, для использования самой системой. Каталоги обеспечивают отображение между двумя этими уровнями имен. Отличием распределенных систем от централизованных является возможность соответствия одному символьному имени нескольких двоичных имен. Обычно это используется для представления оригинального файла и его архивных копий. Имея несколько двоичных имен, можно при недоступности одной из копий файла получить доступ к другой. Этот метод обеспечивает отказоустойчивость за счет избыточности.
Когда два или более пользователей разделяют один файл, необходимо точно определить семантику чтения и записи, чтобы избежать проблем. В централизованных системах, разрешающих разделение файлов, таких как UNIX, обычно определяется, что, когда операция ЧТЕНИЕ следует за операцией ЗАПИСЬ, то читается только что обновленный файл. Аналогично, когда операция чтения следует за двумя операциями записи, то читается файл, измененный последней операцией записи. Тем самым система придерживается абсолютного временного упорядочивания всех операций, и всегда возвращает самое последнее значение. Будем называть эту модель семантикой UNIX'а. В централизованной системе (и даже на мультипроцессоре с разделяемой памятью) ее легко и понять, и реализовать.
Семантика UNIX может быть обеспечена и в распределенных системах, но только, если в ней имеется лишь один файловый сервер, и клиенты не кэшируют файлы. Для этого все операции чтения и записи направляются на файловый сервер, который обрабатывает их строго последовательно. На практике, однако, производительность распределенной системы, в которой все запросы к файлам идут на один сервер, часто становится неудовлетворительной. Эта проблема иногда решается путем разрешения клиентам обрабатывать локальные копии часто используемых файлов в своих личных кэшах. Если клиент сделает локальную копию файла в своем локальном кэше и начнет ее модифицировать, а вскоре после этого другой клиент прочитает этот файл с сервера, то он получит неверную копию файла. Одним из способов устранения этого недостатка является немедленный возврат всех изменений в кэшированном файле на сервер. Такой подход хотя и концептуально прост, но не эффективен.
Другим решением является введение так называемой сессионной семантики, в соответствии с которой изменения в открытом файле сначала виды только процессу, который модифицирует файл, и только после закрытия файла эти изменения могут видеть другие процессы. При использовании сессионной семантики возникает проблема одновременного использования одного и того же файла двумя или более клиентами. Одним из решений этой проблемы является принятие правила, в соответствии с которым окончательным является тот вариант, который был закрыт последним. Менее эффективным, но гораздо более простым в реализации, является вариант, при котором окончательным результирующим файлом на сервере может оказаться любой из этих файлов.
Следующий подход к разделению файлов заключается в том, чтобы сделать все файлы неизменяемыми. Тогда файл нельзя открыть для записи, а можно выполнять только операции СОЗДАТЬ и ЧИТАТЬ. Тогда для изменения файла остается только возможность создать полностью новый файл и поместить его в каталог под именем старого файла. Следовательно, хотя файл и нельзя модифицировать, его можно заменить (автоматически) новым файлом. Другими словами, хотя файлы и нельзя обновлять, но каталоги обновлять можно. Таким образом, проблема, связанная с одновременным использованием файла, просто исчезнет.
Четвертый способ работы с разделяемыми файлами в распределенных системах - это использование механизма неделимых транзакций, достаточно подробно описанного в разделе 3.3.3.
Итак, было рассмотрено четыре различных подхода к работе с разделяемыми файлами в распределенных системах.
Рассмотрим прежде всего вопрос о распределении серверной и клиентской частей между машинами. В некоторых системах (например, NFS) нет разницы между клиентом и сервером, на всех машинах работает одно и то же базовое программное обеспечение, так что любая машина, которая хочет предложить файловый сервис, свободно может это сделать. Для этого ей достаточно экспортировать имена выбранных каталогов, чтобы другие машины могли иметь к ним доступ.
В других системах файловый сервер - это только пользовательская программа, так что система может быть сконфигурирована как клиент, как сервер или как клиент и сервер одновременно. Третьим, крайним случаем, является система, в которой клиенты и серверы - это принципиально различные машины, как в терминах аппаратуры, так и в терминах программного обеспечения. Серверы могут даже работать под управлением другой операционной системы.
Вторым важным вопросом реализации файловой системы является структуризация сервиса файлов и каталогов. Один подход заключается в комбинировании этих двух сервисов на одном сервере. При другом подходе эти сервисы разделяются. В последнем случае при открытии файла требуется обращение к серверу каталогов, который отображает символьное имя в двоичное, а затем обращение к файловому серверу с двоичным именем для действительного чтения или записи файла.
Аргументом в пользу разделения сервисов является тот факт, что они на самом деле слабо связаны, поэтому их раздельная реализация более гибкая. Например, можно реализовать сервер каталогов MS-DOS и сервер каталогов UNIX, которые будут использовать один и тот же файловый сервер для физического хранения файлов. Разделение этих функций также упрощает программное обеспечение. Недостатком является то, что использование двух серверов увеличивает интенсивность сетевого обмена.
Постоянный поиск имен, особенно при использовании нескольких серверов каталогов, может приводить к большим накладным расходам. В некоторых системах делается попытка улучшить производительность за счет кэширования имен. При открытии файла кэш проверяется на наличие в нем нужного имени. Если оно там есть, то этап поиска, выполняемый сервером каталогов, пропускается, и двоичный адрес извлекается из кэша.
Последний рассматриваемый здесь структурный вопрос связан с хранением на серверах информации о состоянии клиентов. Существует две конкурирующие точки зрения.
Первая состоит в том, что сервер не должен хранить такую информацию (сервер stateless). Другими словами, когда клиент посылает запрос на сервер, сервер его выполняет, отсылает ответ, а затем удаляет из своих внутренних таблиц всю информацию о запросе. Между запросами на сервере не хранится никакой текущей информации о состоянии клиента. Другая точка зрения состоит в том, что сервер должен хранить такую информацию (сервер statefull).
Рассмотрим эту проблему на примере файлового сервера, имеющего команды ОТКРЫТЬ, ПРОЧИТАТЬ, ЗАПИСАТЬ и ЗАКРЫТЬ файл. Открывая файлы, statefull-сервер должен запоминать, какие файлы открыл каждый пользователь. Обычно при открытии файла пользователю дается дескриптор файла или другое число, которое используется при последующих вызовах для его идентификации. При поступлении вызова, сервер использует дескриптор файла для определения, какой файл нужен. Таблица, отображающая дескрипторы файлов на сами файлы, является информацией о состоянии клиентов.
Для сервера stateless каждый запрос должен содержать исчерпывающую информацию (полное имя файла, смещение в файле и т.п.), необходимую серверу для выполнения требуемой операции. Очевидно, что эта информация увеличивает длину сообщения.
Однако при отказе statefull-сервера теряются все его таблицы, и после перезагрузки неизвестно, какие файлы открыл каждый пользователь. Последовательные попытки провести операции чтения или записи с открытыми файлами будут безуспешными. Stateless-серверы в этом плане являются более отказоустойчивыми, и это аргумент в их пользу.
Преимущества обоих подходов можно обобщить следующим образом:
Stateless-серверы:
Statefull-серверы:
В системах, состоящих из клиентов и серверов, потенциально имеется четыре различных места для хранения файлов и их частей: диск сервера, память сервера, диск клиента (если имеется) и память клиента. Наиболее подходящим местом для хранения всех файлов является диск сервера. Он обычно имеет большую емкость, и файлы становятся доступными всем клиентам. Кроме того, поскольку в этом случае существует только одна копия каждого файла, то не возникает проблемы согласования состояний копий.
Проблемой при использовании диска сервера является производительность. Перед тем, как клиент сможет прочитать файл, файл должен быть переписан с диска сервера в его оперативную память, а затем передан по сети в память клиента. Обе передачи занимают время.
Значительное увеличение производительности может быть достигнуто за счет кэширования файлов в памяти сервера. Требуются алгоритмы для определения, какие файлы или их части следует хранить в кэш-памяти.
При выборе алгоритма должны решаться две задачи. Во-первых, какими единицами оперирует кэш. Этими единицами могут быть или дисковые блоки, или целые файлы. Если это целые файлы, то они могут храниться на диске непрерывными областями (по крайней мере в виде больших участков), при этом уменьшается число обменов между памятью и диском а, следовательно, обеспечивается высокая производительность. Кэширование блоков диска позволяет более эффективно использовать память кэша и дисковое пространство.
Во-вторых, необходимо определить правило замены данных при заполнении кэш-памяти. Здесь можно использовать любой стандартный алгоритм кэширования, например, алгоритм LRU (least recently used), соответствии с которым вытесняется блок, к которому дольше всего не было обращения.
Кэш-память на сервере легко реализуется и совершенно прозрачна для клиента. Так как сервер может синхронизировать работу памяти и диска, с точки зрения клиентов существует только одна копия каждого файла, так что проблема согласования не возникает.
Хотя кэширование на сервере исключает обмен с диском при каждом доступе, все еще остается обмен по сети. Существует только один путь избавиться от обмена по сети - это кэширование на стороне клиента, которое, однако, порождает много сложностей.
Так как в большинстве систем используется кэширование в памяти клиента, а не на его диске, то мы рассмотрим только этот случай. При проектировании такого варианта имеется три возможности размещения кэша (рисунок 3.11). Самый простой состоит в кэшировании файлов непосредственно внутри адресного пространства каждого пользовательского процесса. Обычно кэш управляется с помощью библиотеки системных вызов. По мере того, как файлы открываются, закрываются, читаются и пишутся, библиотека просто сохраняет наиболее часто используемые файлы. Когда процесс завершается, все модифицированные файлы записываются назад на сервер. Хотя эта схема реализуется с чрезвычайно низкими издержками, она эффективна только тогда, когда отдельные процессы часто повторно открывают и закрывают файлы. Таким является процесс менеджера базы данных, но обычные программы чаще всего читают каждый файл однократно, так что кэширование с помощью библиотеки в этом случае не дает выигрыша.
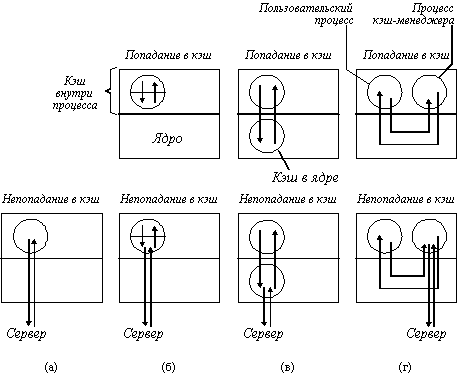
Рис. 3.11. Различные способы выполнения кэша в клиентской памяти
а - без кэширования; б - кэширование внутри каждого процесса; в - кэширование в ядре;
г - кэш-менеджер как пользовательский процесс
Другим местом кэширования является ядро. Недостатком этого варианта является то, что во всех случаях требуется выполнять системные вызовы, даже в случае успешного обращения к кэш-памяти (файл оказался в кэше). Но преимуществом является то, что файлы остаются в кэше и после завершения процессов. Например, предположим, что двухпроходный компилятор выполняется, как два процесса. Первый проход записывает промежуточный файл, который читается вторым проходом. На рисунке 3.11,в показано, что после завершения процесса первого прохода промежуточный файл, вероятно, будет находиться в кэше, так что вызов сервера не потребуется.
Третьим вариантом организации кэша является создание отдельного процесса пользовательского уровня - кэш-менеджера. Преимущество этого подхода заключается в том, что ядро освобождается от кода файловой системы и тем самым реализуются все достоинства микроядер.
С другой стороны, когда ядро управляет кэшем, оно может динамически решить, сколько памяти выделить для программ, а сколько для кэша. Когда же кэш-менеджер пользовательского уровня работает на машине с виртуальной памятью, то понятно, что ядро может решить выгрузить некоторые, или даже все страницы кэша на диск, так что для так называемого "попадания в кэш" требуется подкачка одной или более страниц. Нечего и говорить, что это полностью дискредитирует идею кэширования. Однако, если в системе имеется возможность фиксировать некоторые страницы в памяти, то такая парадоксальная ситуация может быть исключена.
Как и везде, нельзя получить что-либо, не заплатив чем-то за это. Кэширование на стороне клиента вносит в систему проблему несогласованности данных.
Одним из путей решения проблемы согласования является использование алгоритма сквозной записи. Когда кэшируемый элемент (файл или блок) модифицируется, новое значение записывается в кэш и одновременно посылается на сервер. Теперь другой процесс, читающий этот файл, получает самую последнюю версию.
Один из недостатков алгоритма сквозной записи состоит в том, что он уменьшает интенсивность сетевого обмена только при чтении, при записи интенсивность сетевого обмена та же самая, что и без кэширования. Многие разработчики систем находят это неприемлемым и предлагают следующий алгоритм, использующий отложенную запись: вместо того, чтобы выполнять запись на сервер, клиент просто помечает, что файл изменен. Примерно каждые 30 секунд все изменения в файлах собираются вместе и отсылаются на сервер за один прием. Одна большая запись обычно более эффективна, чем много маленьких.
Следующим шагом в этом направлении является принятие сессионной семантики, в соответствии с которой запись файла на сервер производится только после его закрытия. Этот алгоритм называется "запись-по-закрытию". Как мы видели раньше, этот путь приводит к тому, что если две копии одного файла кэшируются на разных машинах и последовательно записываются на сервер, то второй записывается поверх первого. Однако это не так уж плохо, как кажется на первый взгляд. В однопроцессорной системе два процесса могут открыть и читать файл, модифицировать его в своих адресных пространствах, а затем записать его назад. Следовательно, алгоритм "запись-по-закрытию", основанный на сессионной семантике, не намного хуже варианта, уже используемого в однопроцессорной системе.
Совершенно отличный подход к проблеме согласования - это использование алгоритма централизованного управления (этот подход соответствует семантике UNIX). Когда файл открыт, машина, открывшая его, посылает сообщение файловому серверу, чтобы оповестить его об этом факте. Файл-сервер сохраняет информацию о том, кто открыл какой файл, и о том, открыт ли он для чтения, для записи, или для того и другого. Если файл открыт для чтения, то нет никаких препятствий для разрешения другим процессам открыть его для чтения, но открытие его для записи должно быть запрещено. Аналогично, если некоторый процесс открыл файл для записи, то все другие виды доступа должны быть предотвращены. При закрытии файла также необходимо оповестить файл-сервер для того, чтобы он обновил свои таблицы, содержащие данные об открытых файлах. Модифицированный файл также может быть выгружен на сервер в такой момент.
Четыре алгоритма управления кэшированием обобщаются следующим образом:
1. Сквозная запись. Этот метод эффективен частично, так как уменьшает интенсивность только операций чтения, а интенсивность операций записи остается неизменной.
2. Отложенная запись. Производительность лучше, но результат чтения кэшированного файла не всегда однозначен.
3. "Запись-по-закрытию". Удовлетворяет сессионной семантике.
4. Централизованное управление. Ненадежен вследствие своей централизованной природы.
Подводя итоги обсуждения проблемы кэширования, нужно отметить, что кэширование на сервере несложно реализуется и почти всегда дает эффект, независимо от того, реализовано кэширование у клиента или нет. Кэширование на сервере не влияет на семантику файловой системы, видимую клиентом. Кэширование у клиента напротив дает увеличение производительности, но увеличивает и сложность семантики.
Распределенные системы часто обеспечивают репликацию (тиражирование) файлов в качестве одной из услуг, предоставляемых клиентам. Репликация - это асинхронный перенос изменений данных исходной файловой системы в файловые системы, принадлежащие различным узлам распределенной файловой системы. Другими словами, система оперирует несколькими копиями файлов, причем каждая копия находится на отдельном файловом сервере. Имеется несколько причин для предоставления этого сервиса, главными из которых являются:
1. Увеличение надежности за счет наличия независимых копий каждого файла на разных файл-серверах.
2. Распределение нагрузки между несколькими серверами.
Как обычно, ключевым вопросом, связанным с репликацией является прозрачность. До какой степени пользователи должны быть в курсе того, что некоторые файлы реплицируются? Должны ли они играть какую-либо роль в процессе репликации или репликация должна выполняться полностью автоматически? В одних системах пользователи полностью вовлечены в этот процесс, в других система все делает без их ведома. В последнем случае говорят, что система репликационно прозрачна.
На рисунке 3.12 показаны три возможных способа репликации. При использовании первого способа (а) программист сам управляет всем процессом репликации. Когда процесс создает файл, он делает это на одном определенном сервере. Затем, если пожелает, он может сделать дополнительные копии на других серверах. Если сервер каталогов разрешает сделать несколько копий файла, то сетевые адреса всех копий могут быть ассоциированы с именем файла, как показано на рисунке снизу, и когда имя найдено, это означает, что найдены все копии. Чтобы сделать концепцию репликации более понятной, рассмотрим, как может быть реализована репликация в системах, основанных на удаленном монтировании, типа UNIX. Предположим, что рабочий каталог программиста имеет имя /machine1/usr/ast. После создания файла, например, /machine1/usr/ast/xyz, программист, процесс или библиотека могут использовать команду копирования для того, чтобы сделать копии /machine2/usr/ast/xyz и machine3/usr/ast/xyz. Возможно программа использует в качестве аргумента строку /usr/ast/xyz и последовательно попытается открывать копии, пока не достигнет успеха. Эта схема хотя и работает, но имеет много недостатков, и по этим причинам ее не стоит использовать в распределенных системах.
На рисунке 3.12,б показан альтернативный подход - ленивая репликация. Здесь создается только одна копия каждого файла на некотором сервере. Позже сервер сам автоматически выполнит репликации на другие серверы без участия программиста. Эта система должна быть достаточно быстрой для того, чтобы обновлять все эти копии, если потребуется.
Последним рассмотрим метод, использующий групповые связи (рисунок 3.12,в). В этом методе все системные вызовы ЗАПИСАТЬ передаются одновременно на все серверы, таким образом копии создаются одновременно с созданием оригинала. Имеется два принципиальных различия в использовании групповых связей и ленивой репликации. Во-первых, при ленивой репликации адресуется один сервер, а не группа. Во-вторых, ленивая репликация происходит в фоновом режиме, когда сервер имеет промежуток свободного времени, а при групповой репликации все копии создаются в одно и то же время.
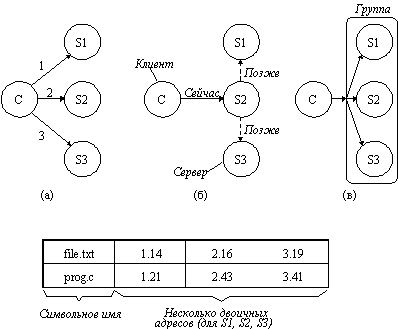
Рис. 3.12. а) Точная репликация файла; б) Ленивая репликация файла;
в) Репликация файла, использующая группу
Рассмотрим, как могут быть изменены существующие реплицированные файлы. Существует два хорошо известных алгоритма решения этой проблемы.
Первый алгоритм, называемый "репликация первой копии", требует, чтобы один сервер был выделен как первичный. Остальные серверы являются вторичными. Когда реплицированный файл модифицируется, изменение посылается на первичный сервер, который выполняет изменения локально, а затем посылает изменения на вторичные серверы.
Чтобы предотвратить ситуацию, когда из-за отказа первичный сервер не успевает оповестить об изменениях все вторичные серверы, изменения должны быть сохранены в постоянном запоминающем устройстве еще до изменения первичной копии. В этом случае после перезагрузки сервера есть возможность сделать проверку, не проводились ли какие-нибудь обновления в момент краха. Недостаток этого алгоритма типичен для централизованных систем - пониженная надежность. Чтобы избежать его, используется метод, предложенный Гиффордом и известный как "голосование". Пусть имеется n копий, тогда изменения должны быть внесены в любые W копий. При этом серверы, на которых хранятся копии, должны отслеживать порядковые номера их версий. В случае, когда какой-либо сервер выполняет операцию чтения, он обращается с запросом к любым R серверам. Если R+W > n, то, хотя бы один сервер содержит последнюю версию, которую можно определить по максимальному номеру.
Интересной модификацией этого алгоритма является алгоритм "голосования с приведениями". В большинстве приложений операции чтения встречаются гораздо чаще, чем операции записи, поэтому R обычно делают небольшим, а W - близким к N. При этом выход из строя нескольких серверов приводит к отсутствию кворума для записи. Голосование с приведениями решает эту проблему путем создания фиктивного сервера без дисков для каждого отказавшего или отключенного сервера. Фиктивный сервер не участвует в кворуме чтения (прежде всего, у него нет файлов), но он может присоединиться к кворуму записи, причем он просто записывает в никуда передаваемый ему файл. Запись только тогда успешна, когда хотя бы один сервер настоящий.
Когда отказавший сервер перезапускается, то он должен получить кворум чтения для обнаружения последней версии, которую он копирует к себе перед тем, как начать обычные операции. В остальном этот алгоритм подобен основному.