| Сервер Информационных Технологий содержит море(!) аналитической информации |
Сервер поддерживается |
|---|
| Сервер Информационных Технологий содержит море(!) аналитической информации |
Сервер поддерживается |
|---|
В основе UNIX лежит концепция процесса - единицы управления и единицы потребления ресурсов. Процесс представляет собой программу в состоянии выполнения, причем в UNIX в рамках одного процесса не могут выполняться никакие параллельные действия.
Каждый процесс работает в своем виртуальном адресном пространстве. Совокупность участков физической памяти, отображаемых на виртуальные адреса процесса, называется образом процесса.
При управлении процессами операционная система использует два основных типа информационных структур: дескриптор процесса (структура proc) и контекст процесса (структура user).
Дескриптор процесса содержит такую информацию о процессе, которая необходима ядру в течение всего жизненного цикла процесса, независимо от того, находится ли он в активном или пассивном состоянии, находится ли образ процесса в оперативной памяти или выгружен на диск. Дескрипторы отдельных процессов объединены в список, образующий таблицу процессов. Память для таблицы процессов отводится динамически в области ядра. На основании информации, содержащейся в таблице процессов, операционная система осуществляет планирование и синхронизацию процессов. В дескрипторе прямо или косвенно (через указатели на связанные с ним структуры) содержится информация о состоянии процесса, расположении образа процесса в оперативной памяти и на диске, о значении отдельных составляющих приоритета, а также его итоговое значение - глобальный приоритет, идентификатор пользователя, создавшего процесс, информация о родственных процессах, о событиях, осуществления которых ожидает данный процесс и некоторая другая информация.
Контекст процесса содержит менее оперативную, но более объемную часть информации о процессе, необходимую для возобновления выполнения процесса с прерванного места: содержимое регистров процессора, коды ошибок выполняемых процессором системных вызовов, информацию о всех открытых данным процессом файлов и незавершенных операциях ввода-вывода (указатели на структуры file) и другие данные, характеризующие состояние вычислительной среды в момент прерывания. Контекст, так же как и дескриптор процесса, доступен только программам ядра, то есть находится в виртуальном адресном пространстве операционной системы, однако он хранится не в области ядра, а непосредственно примыкает к образу процесса и перемещается вместе с ним, если это необходимо, из оперативной памяти на диск. В UNIX для процессов предусмотрены два режима выполнения: привилегированный режим - "система" и обычный режим - "пользователь". В режиме "пользователь" запрещено выполнение действий, связанных с управлением ресурсами системы, в частности, корректировка системных таблиц, управление внешними устройствами, маскирование прерываний, обработка прерываний. В режиме "система" выполняются программы ядра, а в режиме "пользователь" - оболочка и прикладные программы. При необходимости выполнить привилегированные действия пользовательский процесс обращается с запросом к ядру в форме так называемого системного вызова. В результате системного вызова управление передается соответствующей программе ядра. С момента начала выполнения системного вызова процесс считается системным. Таким образом, один и тот же процесс может находиться в пользовательской и системной фазах. Эти фазы никогда не выполняются одновременно.
В данных версиях UNIX процесс, работающий в режиме системы, не мог быть вытеснен другим процессом. Из-за этого организация ядра, которое составляет привилегированную общую часть всех процессов, упрощалась, т.к. все функции ядра не были реентерабельными. Однако, при этом реактивность системы страдала - любой процесс, даже низкоприоритетный, войдя в системную фазу, мог оставаться в ней сколь угодно долго. Из-за этого свойства UNIX не мог использоваться в качестве ОС реального времени. В более поздних версиях, и в SVR4 в том числе, организация ядра усложнилась и процесс можно вытеснить и в системной фазе, но не в произвольный момент времени, а только в определенные периоды его работы, когда процесс сам разрешает это сделать установкой специального сигнала.
В SVR4 имеется несколько процессов, которые не имеют пользовательской фазы, например, процесс pageout, организующий выталкивание страниц на диск.
Порождение процессов в системе UNIX происходит следующим образом. При создании процесса строится образ порожденного процесса, являющийся точной копией образа породившего процесса. Сегмент данных и сегмент стека отца действительно копируются на новое место, образуя сегменты данных и стека сына. Процедурный сегмент копируется только тогда, когда он не является разделяемым. В противном случае сын становится еще одним процессом, разделяющим данный процедурный сегмент.
После выполнения системного вызова fork оба процесса продолжают выполнение с одной и той же точки. Чтобы процесс мог опознать, является ли он отцом или сыном, системный вызов fork возвращает в качестве своего значения в породивший процесс идентификатор порожденного процесса, а в порожденный процесс NULL. Типичное разветвление на языке C записывается так:
if( fork() ) { действия отца }
else { действия сына }
Идентификатор сына может быть присвоен переменной, входящей в контекст процесса-отца. Так как контекст процесса наследуется его потомками, то дети могут узнать идентификаторы своих старших братьев, так образом сумма знаний наследуется при порождении и может быть распространена между родственными процессами. Наследуются все характеристики процесса, содержащиеся в контексте.
На независимости идентификатора процесса от выполняемой процессом программы построен механизм, позволяющий процессу придти к выполнению другой программы с помощью системного вызова exec.
Таким образом в UNIX порождение нового процесса происходит в два этапа - сначала создается копия процесса-родителя, то есть дублируется дескриптор, контекст и образ процесса. Затем у нового процесса производится замена кодового сегмента на заданный.
Вновь созданному процессу операционная система присваивает целочисленный идентификатор, уникальный за весь период функционирования системы.
В системе UNIX System V Release 4 реализована вытесняющая многозадачность, основанная на использовании приоритетов и квантования.
Все процессы разбиты на несколько групп, называемых классами приоритетов. Каждая группа имеет свои характеристики планирования процессов.
Созданный процесс наследует характеристики планирования процесса-родителя, которые включают класс приоритета и величину приоритета в этом классе. Процесс остается в данном классе до тех пор, пока не будет выполнен системный вызов, изменяющий его класс.
В UNIX System V Release 4 возможно включение новых классов приоритетов при инсталляции системы. В настоящее время имеется три приоритетных класса: класс реального времени, класс системных процессов и класс процессов разделения времени. В отличие от ранних версий UNIX приоритетность (привилегии) процесса тем выше, чем больше число, выражающее приоритет. На рисунке 5.2 показаны диапазоны изменения приоритетов для разных классов. Значения приоритетов определяются для разных классов по разному.
Процессы системного класса используют стратегию фиксированных приоритетов. Системный класс зарезервирован для процессов ядра. Уровень приоритета процессу назначается ядром и никогда не изменяется. Заметим, что пользовательский процесс, перешедший в системную фазу, не переходит при этом в системный класс приоритетов.
Процессы реального времени также используют стратегию фиксированных приоритетов, но пользователь может их изменять. Так как при наличии готовых к выполнению процессов реального времени другие процессы не рассматриваются, то процессы реального времени надо тщательно проектировать, чтобы они не захватывали процессор на слишком долгое время. Характеристики планирования процессов реального времени включают две величины: уровень глобального приоритета и квант времени. Для каждого уровня приоритета имеется по умолчанию своя величина кванта времени. Процессу разрешается захватывать процессор на указанный квант времени, а по его истечении планировщик снимает процесс с выполнения.
| Приоритетный класс | Выбор планировщика | Глобальное значение приоритета | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Реальное время (real time) | первый . . . . | 159 . . . 100 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Системные процессы (system) | . . . . . . . . | 99 . . . . . . 60 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Процессы разделения времени (time-shared) | . . . . . . . последний | 59 . . . . . . 0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Возможно добавление новых классов | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 5.2. Приоритетные классы процессов
Процессы разделения времени были до появления UNIX System V Release 4 единственным классом процессов, и по умолчанию UNIX System V Release 4 назначает новому процессу этот класс. Состав класса процессов разделения времени наиболее неопределенный и часто меняющийся, в отличие от системных процессов и процессов реального времени. Для справедливого распределения времени процессора между процессами, в этом классе используется стратегия динамических приоритетов, которая адаптируется к операционным характеристикам процесса.
Величина приоритета, назначаемого процессам разделения времени, вычисляется пропорционально значениям двух составляющих: пользовательской части и системной части. Пользовательская часть приоритета может быть изменена суперпользователем и владельцем процесса, но в последнем случае только в сторону его снижения.
Системная составляющая позволяет планировщику управлять процессами в зависимости от того, как долго они используют процессор, не уходя в состояние ожидания. Тем процессам, которые потребляют большие периоды времени без ухода в состояние ожидания, приоритет снижается, а тем процессам, которые часто уходят в состояние ожидания после короткого периода использования процессора, приоритет повышается. Таким образом, процессам, ведущим себя не по-джентльменски, дается низкий приоритет, что означает, что они реже выбираются на выполнение. Но процессам с низким приоритетом даются большие кванты времени, чем процессам с высокими приоритетами. Таким образом, хотя низкоприоритетный процесс и не работает так часто, как высокоприоритетный, но зато, когда он наконец выбирается на выполнение, ему отводится больше времени.
Планировщик использует следующие характеристики для процессов разделения времени:
| ts_globpri | содержит величину глобального приоритета; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ts_quantum | определяет количество тиков системных часов, которые отводятся процессу до его вытеснения; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ts_tqexp | системная часть приоритета, назначаемая процессу при истечении его кванта времени; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ts_slpret | системная составляющая приоритета, назначаемая процессу после выхода его из состояния ожидания; ожидающим процессам дается высокий приоритет, так что они быстро получают доступ к процессору после освобождения ресурса; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ts_maxwaite | максимальное число секунд, которое разрешается потреблять процессу; если этот квант времени истекает до кванта ts_quantum, то, следовательно, считается, что процесс ведет себя по-джентльменски, и ему назначается более высокий приоритет; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ts_lwait | величина системной части приоритета, назначаемая процессу, если истекает ts_maxwait секунд. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Для процессов разделения времени в дескрипторе процесса proc имеется указатель на структуру, специфическую для данного класса процесса. Эта структура состоит из полей, используемых для вычисления глобального приоритета:
| ts_timeleft | число тиков, остающихся в кванте процесса; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ts_cpupri | системная часть приоритета процесса; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ts_uprilim, ts_upri | верхний предел и текущее значение пользовательской части приоритета. Эти две переменные могут модифицироваться пользователем; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ts_nice | используется для обратной совместимости с системным вызовом nice. Она содержит текущее значение величины nice, которая влияет на результирующую величину приоритета. Чем выше эта величина, тем меньше приоритет. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
В версии SVR4 нет поддержки многонитевой (multithreading) организации процессов на уровне ядра, хотя и есть два системных вызова для организации нитей в пользовательском режиме. Во многих коммерческих реализациях UNIX, базирующихся на кодах SVR4, в ядро включена поддержка нитей за счет собственной модификации исходных текстов SVR4.
В UNIX System V Release 4 реализован механизм виртуальной файловой системы VFS (Virtual File System), который позволяет ядру системы одновременно поддерживать несколько различных типов файловых систем. Механизм VFS поддерживает для ядра некоторое абстрактное представление о файловой системе, скрывая от него конкретные особенности каждой файловой системы.
Типы файловых систем, поддерживаемых в UNIX System V Release 4:
Не во всех коммерческих реализациях поддерживаются все эти файловые системы, отдельные производители могут предоставлять только некоторые из них.
Типы файлов
Файловая система UNIX s5 поддерживает логическую организацию файла в виде последовательности байтов. По функциональному назначению различаются обычные файлы, каталоги и специальные файлы.
Обычные файлы содержат ту информацию, которую заносит в них пользователь или которая образуется в результате работы системных и пользовательских программ, то есть ОС не накладывает никаких ограничений на структуру и характер информации, хранимой в обычных файлах.
Каталог - файл, содержащий служебную информацию файловой системы о группе файлов, входящих в данный каталог. В каталог могут входить обычные, специальные файлы и каталоги более низкого уровня.
Специальный файл - фиктивный файл, ассоциируемый с каким-либо устройством ввода-вывода, используется для унификации механизма доступа к файлам и внешним устройствам.
Структура файловой системы
Файловая система s5 имеет иерархическую структуру, в которой уровни создаются за счет каталогов, содержащих информацию о файлах более низкого уровня. Каталог самого верхнего уровня называется корневым и имеет имя root. Иерархическая структура удобна для многопользовательской работы: каждый пользователь локализуется в своем каталоге или поддереве каталогов, и вместе с тем все файлы в системе логически связаны. Корневой каталог файловой системы всегда располагается на системном устройстве (диск, имеющий такой признак). Однако это не означает, что и все остальные файлы могут содержаться только на нем. Для связи иерархий файлов, расположенных на разных носителях, применяется монтирование файловой системы, выполняемое системным вызовом mount. Пусть имеются две файловые системы, расположенные на разных дисках (рисунок 5.3). Операция монтирования заключается в следующем: в корневой файловой системе выбирается некоторый существующий каталог, содержащий один пустой файл, в данном примере каталог man, содержащий файл dummy. После выполнения монтирования выбранный каталог man становится корневым каталогом второй файловой системы. Через этот каталог смонтированная файловая система подсоединяется как поддерево к общему дереву (рисунок 5.4). При этом нет логической разницы между основной и монтированными файловыми системами.
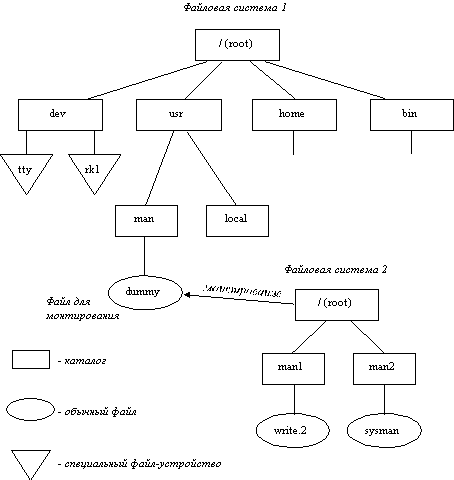
Рис. 5.3. Традиционная файловая система s5
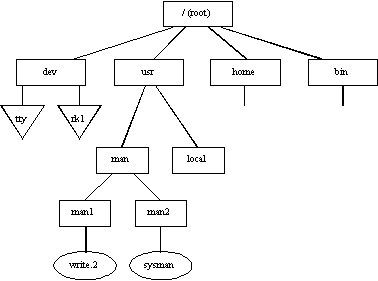
Рис. 5.4. Общая файловая система (после монтирования)
Имена файлов
В UNIX для файла существует три типа имени - краткое, полное и относительное. Краткое имя идентифицирует файл в пределах одного каталога. Оно может состоять не более чем из 14 символов и содержать так называемый суффикс, отделяемый точкой. Полное имя однозначно определяет файл. Оно состоит из цепочки имен каталогов, через которые проходит маршрут от корневого каталога до данного файла. Имена каталогов разделяются символами "/", при этом имя корневого каталога не указывается, например, /mnt/rk2/test.c, где mnt и rk2 - имена каталогов, а test.c - имя файла. Каждому полному имени в ОС соответствует только один файл, однако файл может иметь несколько различных имен, так как ссылки на один и тот же файл могут содержаться в разных каталогах (жесткие связи). Относительное имя файла связано с понятием "текущий каталог", то есть каталог, имя которого задавать не нужно, так как оно подразумевается по умолчанию. Имя файла относительно текущего каталога называется относительным. Оно представляет собой цепочку имен каталогов, через которые проходит маршрут от текущего каталога до данного файла. Относительное имя в отличие от полного не начинается с символа "/". Так, если в предыдущем примере принять за текущий каталог /mnt, то относительное имя файла test.c будет rk2/test.c.
Привилегии доступа
В UNIX s5 все пользователи по отношению к данному файлу делятся на три категории: владелец, член группы владельца и все остальные. Группа - это пользователи, которые объединены по какому-либо признаку, например, по принадлежности к одной разработке. Кроме этого, в системе существует суперпользователь, обладающий абсолютными правами по доступу ко всем файлам системы.
Определены также три вида доступа к файлу - чтение, запись и выполнение. Привилегии доступа к каждому файлу определены для каждой из трех категорий пользователей и для каждой из трех операций доступа. Начальные значения прав доступа к файлу устанавливаются при его создании операционной системой и могут изменяться его владельцем или суперпользователем.
Физическая организация файла
В общем случае файл может располагаться в несмежных блоках дисковой памяти. Логическая последовательность блоков в файле задается набором из 13 элементов. Первые 10 элементов предназначаются для непосредственного указания номеров первых 10 блоков файла. Если размер файла превышает 10 блоков, то в 11 элементе указывается номер блока, в котором содержится список следующих 128 блоков файла. Если файл имеет размер более, чем 10+128 блоков, то используется 12-й элемент, содержащий номер блока, в котором указываются номера 128 блоков, каждый из которых может содержать еще по 128 номеров блоков файла. Таким образом, 12-й элемент используется для двухуровневой косвенной адресации. В случае, если файл больше, чем 10+128+1282 блоков, то используется 13 элемент для трехуровневой косвенной адресации. При таком способе адресации предельный размер файла составляет 2 113 674 блока. Традиционная файловая система s5 поддерживает размеры блоков 512, 1024 или 2048 байт.
Структуры индексных дескрипторов и каталогов
Вся необходимая операционной системе информация о файле, кроме его символьного имени, хранится в специальной системной таблице, называемой индексным дескриптором (inode) файла. Индексные дескрипторы всех файлов имеют одинаковый размер - 64 байта и содержат данные о типе файла, о физическом расположении файла на диске (описанные выше 13 элементов), размере в байтах, о дате создания, последней модификации и последнего обращения к файлу, о привилегиях доступа и некоторую другую информацию. Индексные дескрипторы пронумерованы и хранятся в специальной области файловой системы. Номер индексного дескриптора является уникальным именем файла. Соответствие между полными символьными именами файлов и их уникальными именами устанавливается с помощью иерархии каталогов.
Каталог представляет собой совокупность записей обо всех файлах и каталогах, входящих в него. Каждая запись состоит из 16 байтов, 14 байтов отводится под короткое символьное имя файла или каталога, а 2 байта - под номер индексного дескриптора этого файла. В каталоге файловой системы s5 непосредственно не указываются характеристики файлов. Такая организация файловой системы позволяет с меньшими затратами перестраивать систему каталогов. Например, при включении или исключении файла из каталога идет манипулирование меньшими объемами информации. Кроме того, при включении одного и того же файла в разные каталоги не нужно иметь несколько копий как характеристик, так и самих файлов. С этой целью в индексном дескрипторе ведется учет ссылок на этот файл из всех каталогов. Как только число ссылок становится равным нулю, индексный дескриптор данного файла уничтожается.
Расположение файловой системы s5 на диске показано на рисунке 5.5. Все дисковое пространство, отведенное под файловую систему, делится на четыре области:

Рис. 5.5. Расположение файловой системы s5 на диске
Доступ к файлу осуществляется путем последовательного просмотра всей цепочки каталогов, входящих в полное имя файла, и соответствующих им индексных дескрипторов. Поиск завершается после получения всех характеристик из индексного дескриптора заданного файла. Эта процедура требует в общем случае нескольких обращений к диску, пропорционально числу составляющих в полном имени файла. Для уменьшения среднего времени доступа к файлу его дескриптор копируется в специальную системную область памяти. Копирование индексного дескриптора входит в процедуру открытия файла. При открытии файла ядро выполняет следующие действия:
В UNIX System V Release 3 был реализован механизм переключения файловых систем (File System Switch, FSS), позволяющий операционной системе поддерживать различные типы файловых систем. В соответствии с этим подходом информация о файловой системе и файлах разбивается на две части - зависимую от типа файловой системы и не зависимую. FSS обеспечивает интерфейс между ядром и файловой системой, транслируя запросы ядра в операции, зависящие от типа файловой системы. При этом ядро имеет представление только о независимой части файловой системы. Однако большее распространение получила схема, реализованная фирмой Sun Microsystems, использующая аналогичный подход. Эта схема называется переключателем виртуальной файловой системы - Virtual File System (VFS). В UNIX System V Release 4 реализован именно этот механизм.
VFS не ориентируется на какую-либо конкретную файловую систему, механизмы реализации файловой системы полностью скрыты как от пользователя, так и от приложений. В ОС нет системных вызовов, предназначенных для работы со специфическими типами файловой системы, а имеются абстрактные вызовы типа open, read, write и другие, которые имеют содержательное описание, обобщающее некоторым образом содержание этих операций в наиболее популярных типах файловых систем (например, s5, ufs, nfs и т.п.). VFS также предоставляет ядру возможность оперирования файловой системой, как с единым целым: операции монтирования и демонтирования, а также операции получения общих характеристик конкретной файловой системы (размера блока, количества свободных и занятых блоков и т.п.) в единой форме. Если конкретный тип файловой системы не поддерживает какую-то абстрактную операцию VFS, то файловая система должна вернуть ядру код возврата, извещающий об этом факте.
В VFS вся информация о файлах разделена на две части - не зависящую от типа файловой системы, которая хранится в специальной структуре ядра - структуре vnode, и зависящую от типа файловой системы - структура inode, формат которой на уровне VFS не определен, а используется только ссылка на нее в структуре vnode. Имя inode не означает, что эта структура совпадает со структурой индексного дескриптора inode файловой системы s5. Это имя используется для обозначения зависящей от типа файловой системы информации о файле, как дань традиции.
Виртуальная файловая система VFS поддерживает следующие типы файлов:
Содержательное описание обычных файлов, каталогов и специальных файлов и связей не отличается от их описания в файловой системе s5.
Символьные связи
Версия UNIX System V Release 4 вводит новый тип связи - мягкая связь, называемая символьной связью и реализуемая с помощью системного вызова symlink. Символьная связь - это файл данных, содержащий имя файла, с которым предполагается установить связь. Слово "предполагается" использовано потому, что символьная связь может быть создана даже с несуществующим файлом. При создании символьной связи образуется как новый вход в каталоге, так и новый индексный дескриптор inode. Кроме этого, резервируется отдельный блок данных для хранения полного имени файла, на который он ссылается.
Многие системные вызовы пользуются файлом символьных связей для поиска реального файла. Связанные файлы не обязательно располагаются в той же файловой системе.
Имеются три системных вызова, которые имеют отношение к символьным связям:
Именованные конвейеры
Конвейер - это средство обмена данными между процессами. Конвейер буферизует данные, поступающие на его вход, таким образом, что процесс, читающий данные на его выходе, получает их в порядке "первый пришел - первый вышел" (FIFO). В ранних версиях UNIX для обмена данными между процессами использовались неименованные конвейеры - pipes, которые представляли собой очереди байт в оперативной памяти. Однако, из-за отсутствия имен, такие конвейеры могли использоваться только для передачи данных между родственными процессами, получившими указатель на конвейер в результате копирования сегмента данных из адресного пространства процесса-прародителя. Именованные конвейеры позволяют обмениваться данными произвольной паре процессов, т.к. каждому такому конвейеру соответствует файл на диске. Никакие данные не связываются с файлом-конвейером, но все равно в каталоге содержится запись о нем, и он имеет индексный дескриптор. В UNIX System V Release 4 конвейеры реализуются с использованием коммуникационных модулей STREAMS.
Файлы, отображенные в памяти
Побочным продуктом новой архитектуры виртуальной памяти UNIX System V Release 4 является возможность отображать содержимое файла (или устройства) в виде последовательности байтов в виртуальное адресное пространство процесса. Это упрощает процедуру доступа процесса к данным.
Реализация файловой системы VFS
UNIX System V Release 4 имеет массив структур vfssw [ ], каждая из которых описывает файловую систему конкретного типа, которая может быть установлена в системе. Структура vfssw состоит из четырех полей:
Пример инициализированного массива структур vfssw:
struct vfssw vfssw[] = {
{0, 0 , 0 ,0 }, - нулевой элемент не используется
{"spec", specint, &spec_vfsops, 0}, - SPEC
{"vxfs", vx_init, &vx_vfsops, 0}, - Veritas
{"cdfs", cdfsinit, &cdfs_vfsops, 0}, - CD ROM
{"ufs", ufsinit, &ufs_vfsops, 0}, - UFS
{"s5", vx_init, &vx_vfsops, 0}, - S5
{"fifo", fifoinit, &fifovfsops, 0}, - FIFO
{"dos", dosinit, &dos_vfsops, 0}, - MS-DOS
Функции инициализации файловых систем вызываются во время инициализации операционной системы. Эти функции ответственны за создание внутренней среды файловой системы каждого типа.
Структура vfsops, описывающая операции, которые выполняются над файловой системой, состоит из 7 полей, так как в UNIX System V Release 4 предусмотрено 7 абстрактных операций над файловой системой:
| VFS_MOUNT | монтирование файловой системы, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_UNMOUNT | размонтирование файловой системы, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_ROOT | получение vnode для корня файловой системы, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_STATVFS | получение статистики файловой системы, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_SYNC | выталкивание буферов файловой системы на диск, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_VGET | получение vnode по номеру дескриптора файла, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_MOUNTROOT | монтирование корневой файловой системы. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
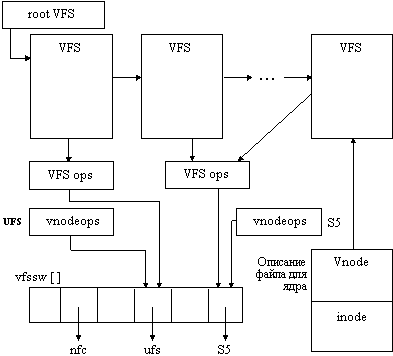
Рис. 5.6. Монтирование файловых систем в VFS
Операция VFS_MOUNT выполняет традиционное для UNIX монтирование файловой системы на указанный каталог уже смонтированной файловой системы для образования общего дерева, а операция VFS_UNMOUNT отменяет монтирование. Операция VFS_ROOT используется при разборе полного имени файла, когда встречается дескриптор vnode, который связан со смонтированной на него файловой системой. Операция VFS_ROOT помогает найти vnode, который является корнем смонтированной файловой системы. Операция VFS_STATVFS позволяет получить независимую от типа файловой системы информацию о размере блока файловой системы, о количестве блоков и количестве свободных блоков в единицах этого размера, о максимальной длине имени файла и т.п. Операция VFS_SYNC выталкивает содержимое буферов диска из оперативной памяти на диск. Операция VFS_MOUNTROOT позволяет смонтировать корневую файловую систему, то есть систему, содержащую корневой каталог / общего дерева. Для указания того, какая файловая система будет монтироваться как корневая, в UNIX System V Release 4 используется переменная rootfstype, содержащая символьное имя корневой файловой системы, например "ufs".
Таким образом, в UNIX System V Release 4 одновременно в единое дерево могут быть смонтированы несколько файловых систем различных типов, поддерживающих операцию монтирования (рисунок 5.6).
| VOP_OPEN | - открыть файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_CLOSE | - закрыть файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_READ | - читать из файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_WRITE | - записать в файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_IOCTL | - управление в/в | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_SETFL | - установить флаги статуса | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_GETATTR | - получить атрибуты файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_SETATTR | - установить атрибуты файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_LOOKUP | - найти vnode по имени файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_CREATE | - создать файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_REMOVE | - удалить файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_LINK | - связать файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_MAP | - отобразить файл в память | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 5.7. Абстрактные операции над файлами
Кроме операций над файловой системой в целом, для каждого типа файловой системы (s5, ufs и т.д.), установленной в ОС, необходимо описать способ реализации абстрактных операций над файлами, которые допускаются в VFS. Этот способ описывается для каждого типа файловой системы в структуре vnodeops, состав которой приведен на рисунке 5.7. Как видно из состава списка абстрактных операций, они образованы объединением операций, характерных для наиболее популярных файловых систем UNIX. Для того, чтобы обращение к специфическим функциям не зависело от типа файловой системы, для каждой операции в vnodeops определен макрос с общим для всех типов файловых систем именем, например, VOP_OPEN, VOP_CLOSE, VOP_READ и т.п. Эти макросы определены в файле <sys/vnode.h> и соответствуют системным вызовам. Таким образом, в структуре vnodeops скрыты зависящие от типа файловой системы реализации стандартного набора операций над файлами. Даже если файловая система какого-либо конкретного типа не поддерживает определенную операцию над своими файлами, она должна создать соответствующую функцию, которая выполняет некоторый минимум действий: или сразу возвращает успешный код завершения, или возвращает код ошибки. Для анализа и обработки полного имени файла в VFS используется операция VOP_LOOKUP, позволяющая по имени файла найти ссылку на его структуру vnode.
Работа ядра с файлами во многом основана на использовании структуры vnode, поля которой представлены на рисунке 5.8. Структура vnode используется ядром для связи файла с определенным типом файловой системы через поле v_vfsp и конкретными реализациями файловых операций через поле v_op. Поле v_pages используется для указания на таблицу физических страниц памяти в случае, когда файл отображается в физическую память (этот механизм описан в разделе, описывающем организацию виртуальной памяти). В vnode также содержится тип файла и указатель на зависимую от типа файловой системы часть описания характеристик файла - структуру inode, обычно содержащую адресную информацию о расположении файла на носителе и о правах доступа к файлу. Кроме этого, vnode используется ядром для хранения информации о блокировках (locks), примененных процессами к отдельным областям файла.
Ядро в своих операциях с файлами оперирует для описания области файла парой vnode, offset, которая однозначно определяет файл и смещение в байтах внутри файла.
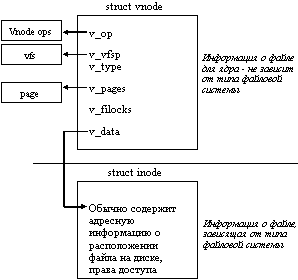
Рис. 5.8. Описатель файла - vnode
При каждом открытии процессом файла ядро создает в системной области памяти новую структуру типа file, которая, как и в случае традиционной файловой системы s5, описывает как открытый файл, так и операции, которые процесс собирается производить с файлом (например, чтение). Структура file содержит такие поля, как:
а также указатели на предыдущую и последующую структуру типа file, связывающие все такие структуры в список.
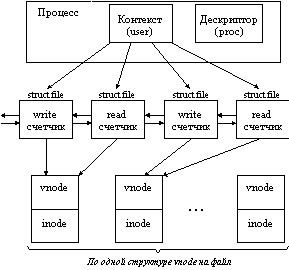
Рис. 5.9. Связь процесса с его файлами
Связь структур процесса с системным списком структур file показан на рисунке 5.9.
В отличие от структур типа file структуры типа vnode заводятся операционной системой для каждого активного (открытого) файла в единственном экземпляре, поэтому структуры file могут ссылаться на одну и ту же структуру vnode.
Структуры vnode не связаны в какой-либо список. Они появляются по требованию в системном пуле памяти и присоединяются к структуре данных, которая инициировала появление этого vnode, с помощью соответствующего указателя. Например, в случае структуры file в ней используется указатель f_vnode на соответствующую структуру vnode, описывающую нужный файл. Аналогично, если файл связан с образом процесса (то есть это файл, содержащий выполняемый модуль), то отображение сегмента памяти, содержащего части этого файла, осуществляется посредством указателя vp (в структуре segvn_data) на vnode этого файла.
Все операции с файлами в UNIX System V Release 4 производятся с помощью связанной с файлом структуры vnode. Когда процесс запрашивает операцию с файлом (например, операцию open), то независимая от типа файловой системы часть ОС передает управление зависимой от типа файловой системы части ОС для выполнения операции. Если зависимая часть обнаруживает, что структуры vnode, описывающей нужный файл, нет в оперативной памяти, то зависимая часть заводит для него новую структуру vnode.
Для ускорения доступа к файлам в UNIX System V Release 4 используется механизм быстрой трансляции имен файлов в соответствующие им ссылки на структуры vnode. Этот механизм основан на наличии кэша, хранящего максимально 800 записей о именах файлов и указателях vnode.
Одной из самых известных сетевых файловых систем является Network File System (NFS) фирмы Sun Microsystems. NFS была первоначально создана для UNIX-компьютеров. Сейчас она поддерживает как UNIX, так и другие ОС, включая MS DOS. NFS поддерживает неоднородные системы, например, MS-DOS-клиенты и UNIX-серверы.
Основная идея NFS - позволить произвольному набору пользователей разделять общую файловую систему. Чаще всего все пользователи принадлежат одной локальной сети, но не обязательно. Можно выполнять NFS и на глобальной сети. Каждый NFS-сервер предоставляет один или более своих каталогов для доступа удаленным клиентам. Каталог объявляется доступным со всеми своими подкаталогами. Список каталогов, которые сервер передает, содержится в файле /etc/exports, так что эти каталоги экспортируются сразу автоматически при загрузке сервера. Клиенты получают доступ к экспортируемым каталогам путем монтирования. Многие рабочие станции Sun - бездисковые, но и в этом случае можно монтировать удаленную файловую систему на корневой каталог, при этом вся файловая система целиком располагается на сервере. При выполнении программ почти нет различий, расположен ли файл локально или на удаленном диске. Если два или более клиента одновременно смонтировали один и тот же каталог, то они могут связываться путем разделения файла.
Так как одной из целей NFS является поддержка неоднородных систем с клиентами и серверами, выполняющими различные ОС на различной аппаратуре, то особенно важно, чтобы был хорошо определен интерфейс между клиентами и серверами. Только в этом случае станет возможным написание программного обеспечения клиентской части для новых операционных систем рабочих станций, которое будет правильно работать с существующими серверами. Это цель достигается двумя протоколами.
Первый NFS-протокол управляет монтированием. Клиент может послать полное имя каталога серверу и запросить разрешение на монтирование этого каталога на какое-либо место собственного дерева каталогов. При этом серверу не указывается, в какое место будет монтироваться каталог сервера, так как ему это безразлично. Получив имя, сервер проверяет законность этого запроса и возвращает клиенту описатель файла, содержащий тип файловой системы, диск, номер дескриптора (inode) каталога, информацию безопасности. Операции чтения и записи файлов из монтируемых файловых систем используют этот описатель файла. Монтирование может выполняться автоматически с помощью командных файлов при загрузке. Существует другой вариант автоматического монтирования: при загрузке ОС на рабочей станции удаленная файловая система не монтируется, но при первом открытии удаленного файла ОС посылает запросы каждому серверу, и, после обнаружения этого файла, монтирует каталог того сервера, на котором этот файл расположен.
Второй NFS-протокол используется для доступа к удаленным файлам и каталогам. Клиенты могут послать запрос серверу для выполнения какого-либо действия над каталогом или операции чтения или записи файла. Кроме того, они могут запросить атрибуты файла, такие как тип, размер, время создания и модификации. Большая часть системных вызовов UNIX поддерживается NFS, за исключением open и close. Исключение open и close не случайно. Вместо операции открытия удаленного файла клиент посылает серверу сообщение, содержащее имя файла, с запросом отыскать его (lookup) и вернуть описатель файла. В отличие от вызова open, вызов lookup не копирует никакую информацию во внутренние системные таблицы сервера. Вызов read содержит описатель того файла, который нужно читать, смещение в уже читаемом файле и количество байтов, которые нужно прочитать. Преимуществом такой схемы является то, что сервер не должен запоминать ничего об открытых файлах. Таким образом, если сервер откажет, а затем будет восстановлен, информация об открытых файлах не потеряется, потому что ее нет. Серверы, подобные этому, не хранящие постоянную информацию об открытых файлах, называются stateless.
В противоположность этому в UNIX System V в удаленной файловой системе RFS требуется, чтобы файл был открыт, прежде чем его можно будет прочитать или записать. После этого сервер создает таблицу, сохраняющую информацию о том, что файл открыт, и о текущем читателе. Недостаток этого подхода состоит в том, что когда сервер отказывает, после его перезапуска все его открытые связи теряются, и программы пользователей портятся. В NFS такого недостатка нет.
К сожалению метод NFS затрудняет блокировку файлов. В UNIX файл может быть открыт и заблокирован так, что другие процессы не имеют к нему доступа. Когда файл закрывается, блокировка снимается. В stateless-системах, подобных NFS, блокирование не может быть связано с открытием файла, так как сервер не знает, какой файл открыт. Следовательно, NFS требует специальных дополнительных средств управления блокированием.
Реализация кодов клиента и сервера в NFS имеет многоуровневую структуру (рисунок 5.10).

Рис. 5.10. Многоуровневая структура NFS
Верхний уровень клиента - уровень системных вызовов, таких как OPEN, READ, CLOSE. После грамматического разбора вызова и проверки параметров, этот уровень обращается ко второму уровню - уровню виртуальной файловой системы (VFS). В структуре vnode имеется информация о том, является ли файл удаленным или локальным. Чтобы понять, как используются vnode, рассмотрим последовательность выполнения системных вызовов MOUNT, READ, OPEN. Чтобы смонтировать удаленную файловую систему, системный администратор вызывает программу монтирования, указывая удаленный каталог, локальный каталог, на который должен монтироваться удаленный каталог, и другую информацию. Программа монтирования выполняет грамматический разбор имени удаленного каталога и определяет имя машины, где находится удаленный каталог. Если каталог существует и является доступным для удаленного монтирования, то сервер возвращает описатель каталога программе монтирования, которая путем выполнения системного вызова MOUNT передает этот описатель в ядро.
Затем ядро создает vnode для удаленного каталога и обращается с запросом к клиент-программе для создания rnode (удаленного inode) в ее внутренних таблицах. Каждый vnode указывает либо на какой-нибудь rnode в NFS клиент-коде, либо на inode в локальной ОС.
В UNIX System V Release 4 реализована сегментно-страничная модель памяти в ее традиционном виде. Наряду с механизмом управления страницами используется и механизм свопинга, когда на диск выталкиваются все страницы какого-либо процесса. Свопинг применяется в "предаварийных" ситуациях, когда размер свободной оперативной памяти уменьшается до некоторого заданного порога, так что работа всей системы очень затрудняется.
На рисунке 5.11 показаны основные структуры, описывающие виртуальное адресное пространство отдельного процесса. В дескрипторе процесса proc содержится указатель на структуру as, с помощью которой описываются все виртуальные сегменты, которыми обладает данный процесс. Элемент a_seg в структуре as указывает на первый дескриптор сегмента процесса. Каждый дескриптор сегмента (структура seg) описывает один виртуальный сегмент процесса. Дескрипторы сегментов процесса связаны в двунаправленный список. Дескриптор сегмента содержит базовый адрес начала сегмента в виртуальном адресном пространстве процесса, размер сегмента, а также указатели на операции, которые допускаются над этим сегментом (дублирование, освобождение, отображение и т.д.).
Имеются следующие типы виртуальных сегментов:
Есть еще два типа сегментов:
Поле s_data дескриптора сегмента указывает на структуру данных segvn_dat, в которой содержится специфическая для сегмента информация:
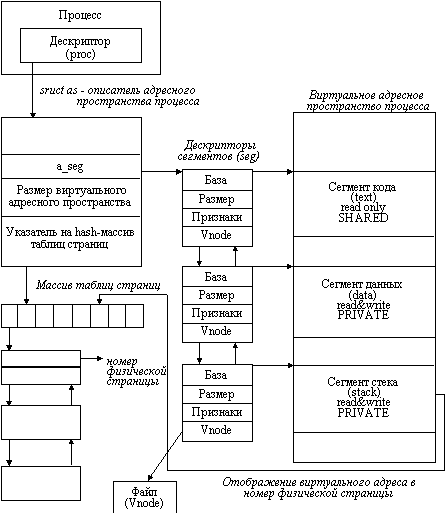
Рис. 5.11. Сегментно-страничная модель виртуальной памяти UNIX
Каждый сегмент имеет связь с дисковым пространством, на котором хранятся данные, отображаемые в данный сегмент виртуального адресного пространства. Это может быть файл или часть файла на диске, или же это может быть область свопинга, которая файлом не является. Сегмент кода или сегмент инициализированных данных обычно связан с файлом, в котором хранится исполняемая программа. Под связью с файлом понимается отображение виртуального сегмента и его страниц на определенную область диска, из которой загружаются данные виртуальных страниц сегмента при их перемещении в оперативную память, а также куда помещаются данные при вытеснении виртуальных страниц на диск. Виртуальные страницы, которые были изначально взяты из определенного файла (который описывается на уровне ядра структурой vnode), называются vnode-страницами, а страницы, которые появились только при развертывании процесса (а это обычно страницы стека или неинициализированных сегментов данных) - анонимными страницами. Однако анонимные страницы также имеют связь с файлом, в который они выталкиваются при их вытеснении из физической памяти (так называемое свопинг-устройство). На свопинг-устройство также указывает vnode, поэтому в этом качестве может выступать любой файл, а перемещение страниц из свопинг-устройства в память осуществляется теми же функциями, что используются для vnode-страниц.
Отображение виртуальных страниц сегмента на физические задается с помощью таблицы HAT (Hardware Address Translation), указатель на которую имеется в структуре адресного пространства процесса as. Структура таблицы HAT зависит от аппаратной платформы, но в любом случае с ее помощью можно найти таблицу или таблицы страниц, содержащих дескрипторы страниц (структуры типа pte). Дескриптор страницы содержит признак наличия данной виртуальной страницы в физической памяти, номер соответствующей физической страницы, а также ряд признаков типа "модификация", "была ссылка", помогающих операционной системе планировать процесс вытеснения виртуальных страниц на диск.
В UNIX System V Release 4 используется алгоритм перемещения виртуальных страниц процесса в физическую память по запросу. Обычно при запуске процесса в физическую память помещается только небольшая часть страниц, необходимая для старта процесса, а остальные страницы загружаются при страничных сбоях. Очевидно, что начальный период работы любого процесса порождает повышенную нагрузку на систему. Если при поиске виртуального адреса в соответствующем дескрипторе обнаруживается признак отсутствия этой страницы в физической памяти, то происходит страничное прерывание, и ядро перемещает эту страницу с диска в физическую память. Для поиска страницы на диске используется информация из структуры s_data сегмента - либо vnode и offset, если страница типа vnode, либо информация о расположении анонимной страницы в области свопинга с помощью информации о ее расположении там по карте amp.
Если в физической памяти недостаточно места для размещения затребованной процессом страницы, то ОС выгружает некоторые страницы на диск. Этот процесс осуществляется специальным процессом ядра, "выталкивателем страниц", имеющем в UNIX System V Release 4 имя pageout. Для принятия решения о том, какую виртуальную страницу нужно переместить на диск, процессу pageout нужно иметь информацию о текущем состоянии физической памяти.
Структура физической памяти
На рисунке 5.12 показан пример распределения физической памяти. В самых нижних адресах находится текстовый сегмент ядра, затем располагается сегмент данных ядра, далее может идти динамический сегмент данных ядра, в котором отводится место для структур ядра, например, для дескрипторов процессов. В оставшейся физической памяти могут располагаться в общем случае несколько областей для хранения страниц пользовательских процессов. Эти области описываются таблицей pageac_table[ ], каждый элемент которой содержит номера начальной и конечной страницы области, указатели на дескрипторы первой и последней страниц, размещенных в этой области.
Для каждой физической страницы имеется дескриптор страницы - структура page, в котором содержится информация о том, свободна или занята страница, загружена ли в нее в данный момент виртуальная страница, модифицировано ли ее содержимое, сколько процессов хотят сохранить эту страницу в памяти и другая информация. В каждый момент времени дескриптор физической страницы может состоять в одном из следующих списков:
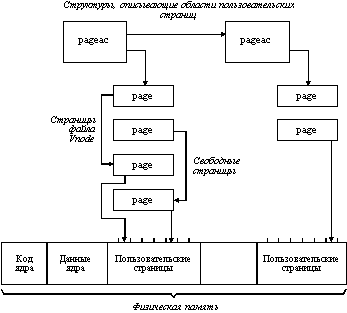
Рис. 5.12. Структуры, описывающие физическую память
Для вытеснения виртуальных страниц с целью освобождения физической памяти в UNIX System V Release 4 используется несколько констант, описывающих размер свободной памяти. Эти константы используются как пороговые значения для действий по освобождению физической памяти (рисунок 5.13). Если свободная память в системе превышает порог lotsfree, то процесс pageout не вызывается вовсе. Если размер свободной физической памяти находится в пределах от desfree до lotsfree, то pagefree вызывается 4 раза в секунду, а если ее размер становится меньше порога desfree, то pagefree вызывается при каждом цикле работы функции clock(). Если же свободная память становится меньше порога GPGSLO, то в действие вступает процесс свопинга, который в UNIX System V Release 4 называется shed. Этот процесс выбирает определенный процесс, а затем выгружает все его страницы на диск, освобождая тем самым сразу значительное место в памяти. Таким образом UNIX System V Release 4 использует механизм свопинга процессов, который был основным механизмом в ранних версиях UNIX для освобождения физической памяти для других процессов. Процесс, выгруженный на диск, исключается из претендентов на выполнение. Через некоторое время процесс shed вызывается снова. Если количество свободной памяти превысило GPGSL, то процесс загружается с диска в память и включается в очередь готовых к выполнению процессов.
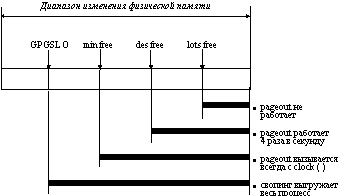
Рис. 5.13. Пороговые значения для действий по освобождению физической памяти
Процесс вытеснения страниц pageout использует при поиске страниц для вытеснения алгоритм NRU (Not Recently Used), выбирающий для вытеснения не используемые в последнее время страницы. Этот алгоритм использует признаки модификации и доступа страниц. Процесс pageout периодически очищает эти признаки у тех страниц, которые не свободны. Если при следующем вызове процесс pageout видит, что эти признаки равны нулю, то значит доступа к этим страницам с момента предыдущего вызова процесса pageout не было, поэтому эти страницы вытесняются на диск. Процесс pageout циклически проверяет все страницы физической памяти, поэтому он называется часовым алгоритмом, что отражает просмотр страниц как бы по часовой стрелке. Было замечено, что обход всех страниц при их большом количестве занимает слишком много времени, поэтому в UNIX System V Release 4 применяется модифицированный часовой алгоритм. Он хорошо иллюстрируется часами с двумя стрелками, которые движутся синхронно, то есть угол между ними сохраняется постоянным. Первая стрелка указывает на виртуальные страницы, признаки которых обнуляются, а вторая - на страницы, признаки которых проверяются и, в случае их равенства нулю, страница вытесняется их физической памяти. При каждом вызове процесс pageout делает лишь часть полного оборота, поэтому при небольшом зазоре между стрелками в памяти остаются только страницы, к которым идет интенсивное обращение.
Основу системы ввода-вывода ОС UNIX составляют драйверы внешних устройств и средства буферизации данных. ОС UNIX использует два различных интерфейса с внешними устройствами: байт-ориентированный и блок-ориентированный.
Любой запрос на ввод-вывод к блок-ориентированному устройству преобразуется в запрос к подсистеме буферизации, которая представляет собой буферный пул и комплекс программ управления этим пулом.
Буферный пул состоит из буферов, находящихся в области ядра. Размер отдельного буфера равен размеру блока данных на диске.
С каждым буфером связана специальная структура - заголовок буфера, в котором содержится следующая информация:
Упрощенный алгоритм выполнения запроса к подсистеме буферизации приведен на рисунке 5.14. Данный алгоритм реализуется набором функций, наиболее важные из которых рассматриваются ниже.
Функция bwrite - синхронная запись. В результате выполнения данной функции немедленно инициируется физический обмен с внешним устройством. Процесс, выдавший запрос, ожидает результат выполнения операции ввода-вывода. В данном случае в процессе может быть предусмотрена собственная реакция на ошибочную ситуацию. Такой тип записи используется тогда, когда необходима гарантия правильного завершения операции ввода-вывода.
Функция bawrite - асинхронная запись. При таком типе записи также немедленно инициируется физический обмен с устройством, однако завершения операции ввода-вывода процесс не дожидается. В этом случае возможные ошибки ввода-вывода не могут быть переданы в процесс, выдавший запрос. Такая операция записи целесообразна при поточной обработке файлов, когда ожидание завершения операции ввода-вывода не обязательно, но есть уверенность в повторении этой операции.
Функция bdwrite - отложенная запись. При этом передача данных из системного буфера не производится, а в заголовке буфера делается отметка о том, что буфер заполнен и может быть выгружен, если потребуется освободить буфер.
Функции bread и getblk - получить блок. Каждая из этих функций ищет в буферном пуле буфер, содержащий указанный блок данных. Если такого блока в буферном пуле нет, то в случае использования функции getblk осуществляется поиск любого свободного буфера, при этом возможна выгрузка на диск буфера, содержащего в заголовке признак отложенной записи. В случае использования функции bread при отсутствии заданного блока в буферном пуле организуется его загрузка в какой-нибудь свободный буфер. Если свободных буферов нет, то также производится выгрузка буфера с отложенной записью. Функция getblk используется тогда, когда содержимое зарезервированного блока не существенно, например, при записи на устройство данных, объем которых равен одному блоку.
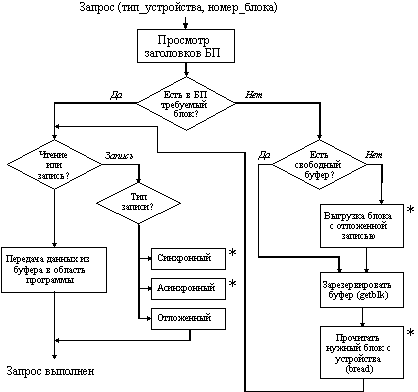
Рис. 5.14. Упрощенная схема выполнения запросов подсистемой буферизации
Таким образом, за счет отложенной записи в системном буферном пуле задерживается некоторое число блоков данных. При возникновении запроса к внешней памяти просматривается содержимое буферного пула. При этом вероятность обнаружения данных в системном пуле достаточно велика. Это обусловлено объективными свойствами пространственной и временной локальности данных. В соответствии с описанным алгоритмом буферизации, в системном буферном пуле оседает наиболее часто используемая информация. Таким образом, система буферизации выполняет роль кэш-памяти по отношению к диску. Кэширование диска уменьшает среднее время доступа к данным на диске, однако при этом снижается надежность файловой системы, так как в случае внезапной потери питания или отказа диска может произойти потеря блоков, содержащихся в системном буфере. Этот недостаток частично компенсируется регулярной (каждую секунду) принудительной записью всех блоков из системной области на диск.
Выше был описан механизм старого буферного кэша, использовавшегося в предыдущих версиях UNIX System V в качестве основного дискового кэша. В UNIX System V Release 4 используется новый механизм, основанный на отображении файлов в физическую память. Однако старый механизм кэширования также сохранен, так как новый кэш используется только для блоков данных файлов, но непригоден для кэширования административной информации диска, такой как inode, каталог и т.д.
Новый буферный кэш
Расположение данных в файле характеризуется их смещением от начала файла. Так как ядро ссылается на любой файл с помощью структуры vnode, то расположение данных в файле определяется парой vnode/offset. Доступ к файлу по адресу vnode/offset достигается с помощью сегмента виртуальной памяти типа segmap, который подобен сегменту segvn, используемому системой виртуальной памяти. Метод доступа к файлам, основанный на сегментах segmap, называется новым буферным кэшем. Этот способ кэширования использует модель страничного доступа к памяти для ссылок на блоки файлов. Размер страницы, используемой новым буферным кэшем, машиннозависим. Для отображения блоков файлов используется адресное пространство ядра, которое также как и пользовательское виртуальное пространство описывается структурой as. Одним из сегментов в адресном пространстве ядра является сегмент segkmap, который используется для страничного доступа к области файлов.
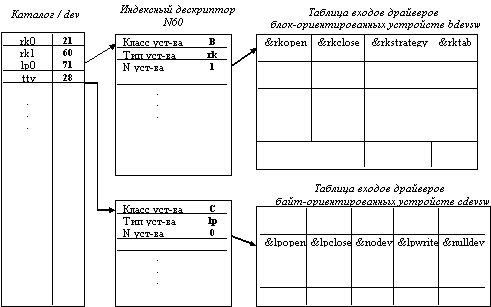
Рис. 5.15. Организация связи ядра с драйверами
Драйвер - это совокупность программ (секций), предназначенная для управления передачей данных между внешним устройством и оперативной памятью.
Связь ядра системы с драйверами (рисунок 5.15) обеспечивается с помощью двух системных таблиц:
Для связи используется следующая информация из индексных дескрипторов специальных файлов:
Класс устройства определяет выбор таблицы bdevsw или cdevsw. Эти таблицы содержат адреса программных секций драйверов, причем одна строка таблицы соответствует одному драйверу. Тип устройства определяет выбор драйвера. Типы устройств пронумерованы, т.е. тип определяет номер строки выбранной таблицы. Номер устройства передается драйверу в качестве параметра, так как в ОС UNIX драйверы спроектированы в расчете на обслуживание нескольких устройств одного типа.
Такая организация логической связи между ядром и драйверами позволяет легко настраивать систему на новую конфигурацию внешних устройств путем модификации таблиц bdevsw и cdevsw.
Драйвер байт-ориентированного устройства в общем случае состоит из секции открытия, чтения и записи файлов, а также секции управления режимом работы устройства. В зависимости от типа устройства некоторые секции могут отсутствовать. Это определенным образом отражено в таблице cdevsw. Секции записи и чтения обычно используются совместно с модулями обработки прерываний ввода-вывода от соответствующих устройств.
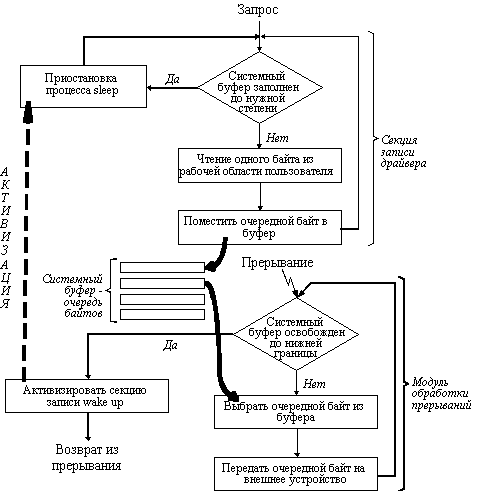
Рис. 5.16. Взаимодействие секции записи драйвера с модулем обработки прерывания
На рисунке 5.16 показано взаимодействие секции записи драйвера байт-ориентированного устройства с модулем обработки прерываний. Секция записи осуществляет передачу байтов из рабочей области программы, выдавшей запрос на обмен, в системный буфер, организованный в виде очереди байтов. Передача байтов идет до тех пор, пока системный буфер не заполнится до некоторого, заранее определенного в драйвере, уровня. В результате секция записи драйвера приостанавливается, выполнив системную функцию sleep (аналог функций типа wait). Модуль обработки прерываний работает асинхронно секции записи. Он вызывается в моменты времени, определяемые готовностью устройства принять следующий байт. Если при очередном прерывании оказывается, что очередь байтов уменьшилась до определенной нижней границы, то модуль обработки прерываний активизирует секцию записи драйвера путем обращения к системной функции wakeup.
Аналогично организована работа при чтении данных с устройства.
Драйвер блок-ориентированного устройства состоит в общем случае из секций открытия и закрытия файлов, а также секции стратегии. Кроме адресов этих секций, в таблице bdevsw указаны адреса так называемых таблиц устройств (rktab). Эти таблицы содержат информацию о состоянии устройства - занято или свободно, указатели на буфера, для которых активизированы операции обмена с данным устройством, а также указатели на цепочку буферов, в которых находятся блоки данных, предназначенные для обмена с данным устройством.
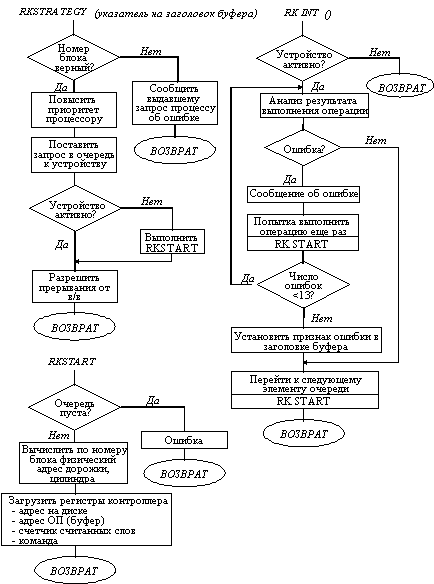
Рис 5.17. Структурная схема драйвера диска типа RK
На рисунке 5.17 приведена упрощенная схема драйвера жесткого диска. Секция стратегии - rkstrategy - выполняет постановку запроса на ввод-вывод в очередь к устройству путем присоединения указанного буфера к цепочке буферов, уже предназначенных для обмена с данным устройством. В случае необходимости секция стратегии запускает устройство (программа rkstart) для выполнения чтения или записи блока с устройства. Вся информация о требуемой операции может быть получена из заголовка буфера, указатель на который передается секции стратегии в качестве аргумента.
После запуска устройства управление возвращается процессу, выдавшему запрос к драйверу.
Об окончании ввода-вывода каждого блока устройство оповещает операционную систему сигналом прерывания. Первое слово вектора прерываний данного устройства содержит адрес секции драйвера - модуля обработки прерываний rkintr. Модуль обработки прерываний проводит анализ правильности выполнения ввода-вывода. Если зафиксирована ошибка, то несколько раз повторяется запуск этой же операции, после чего драйвер переходит к вводу-выводу следующего блока данных из очереди к устройству.