| Сервер Информационных Технологий содержит море(!) аналитической информации |
Сервер поддерживается |
|---|
| Сервер Информационных Технологий содержит море(!) аналитической информации |
Сервер поддерживается |
|---|
Процесс в Mach - это, в первую очередь, адресное пространство и набор нитей, которые выполняются в этом адресном пространстве. Таким образом, выполнение связано с нитями, а процессы являются пассивными объектами и служат для сбора всех ресурсов, использующихся группой взаимосвязанных нитей, в удобные контейнеры.
Рисунок 6.2 иллюстрирует процесс в Mach. Кроме адресного пространства и нитей, процесс характеризуется используемыми им портами и некоторыми параметрами. Все порты, показанные на рисунке, имеют специальное назначение. Порт процесса используется для взаимодействия с ядром. Многие из функций ядра процесс может вызывать путем отправки сообщения на порт процесса, а не с помощью системного вызова. Этот механизм используется в Mach всюду для уменьшения количества системных вызовов до возможного минимума. Некоторые из системных вызовов будут далее обсуждены. Вообще говоря, программист может даже не знать, выполняется ли сервис с помощью системного вызова или нет. Всем сервисам, вызываемым как с помощью системных вызовов, так и с помощью передачи сообщений, соответствуют эрзац-процедуры (заглушки, или стабы) в библиотеке. Это именно те процедуры, которые описаны в руководствах и которые вызываются прикладными программами. Эти процедуры генерируются на основании описания сервиса с помощью компилятора MIG (Mach Interface Generator).
Порт загрузки используется при инициализации, когда система стартует. Самый первый процесс читает из порта загрузки, чтобы узнать имена портов ядра, которые обеспечивают наиболее важные сервисы. Процессы UNIX'а также используют этот порт для взаимодействия с UNIX-эмулятором.
Порт особых ситуаций используется системой для передачи сообщений об ошибках процессу. Примерами особых ситуаций является деление на ноль, неправильный код команды. Этот порт также используют отладчики.
Зарегистрированные порты обычно используются для обеспечения возможностей взаимодействия между процессами и стандартными системными серверами.
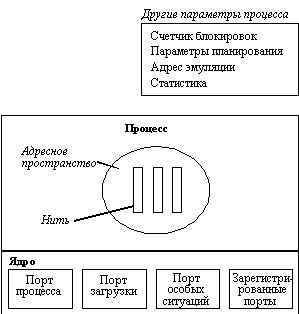
Рис. 6.2. Процесс Mach
Процессы также обладают и другими свойствами. Процесс может быть выполняемым или заблокированным, независимо от состояния его нитей. Если процесс является выполняемым, то те его нити, которые также готовы к выполнению, могут планироваться и выполняться. Если процесс заблокирован, то все его нити не могут выполняться независимо от их состояния.
Параметры планирования, помимо нитей, определяются также для процессов. Эти параметры включают возможность определения того, на каких процессорах могут выполняться нити данного процесса. Это свойство наиболее полезно для многопроцессорных систем. Например, процесс может использовать это свойство для того, чтобы заставить выполняться нить на разных процессорах, или заставить все нити работать на одном процессоре, или реализовать какой-нибудь промежуточный вариант. Кроме того, каждый процесс имеет приоритет, который можно устанавливать. При создании нити ей присваивается этот приоритет. Также имеется возможность изменять приоритет всех существующих нитей.
Наконец, каждый процесс имеет статистику, например, о количестве используемой памяти, временах выполнения нитей и т.д. Любой другой процесс, который интересуется этой статистикой, может получить ее, послав сообщение на порт данного процесса.
Также полезно упомянуть, чем не обладает процесс Mach по сравнению с процессами UNIX'а. Процесс не содержит: идентификатор пользователя, групповой идентификатор, маску сигналов, корневой каталог, рабочий каталог, массив дескрипторов файлов. Вся эта информация содержится в параметрах процесса на уровне сервера пользовательского режима.
Mach предусматривает небольшое количество примитивов управления процессами. Большинство из них выполняется путем посылки сообщения ядру через порт процесса. Наиболее важные из этих вызовов приведены в таблице 6.1.
Первые два вызова предназначены для создания и уничтожения процессов. Вызов Create определяет прототип процесса, которым не обязательно является вызывающий процесс. Потомок является копией прототипа, за исключением случая наследования родительского адресного пространства, который определяется заданием параметра. Если адресное пространство не наследуется, то объекты (например, текст, инициализированные данные и стек) могут быть отображены в него позже. Изначально потомок не имеет нитей. Однако он автоматически наследует порты загрузки, процесса и особых ситуаций. Другие порты автоматически не наследуются.
Таблица 6.1.
| Вызов | Описание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Create | Создает новый процесс, наследующий некоторые свойства | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Terminate | Завершает определенный процесс | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Suspend | Наращивает счетчик приостановок | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Resume | Уменьшает счетчик приостановок; если он равен 0, то разблокирует процесс | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Priority | Устанавливает приоритет для существующих или будущих нитей | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Assign | Говорит, на каком процессоре должны выполняться новые нити | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Info | Возвращает информацию о времени выполнения, используемой памяти и т.д. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Threads | Возвращает список нитей процесса | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Процессы могут быть приостановлены и возобновлены с помощью программного управления. Каждый процесс имеет счетчик, наращиваемый вызовом Suspend и уменьшаемый вызовом Resume, которые могут блокировать и разблокировать его. Когда счетчик равен 0, то процесс может выполняться. Наличие счетчика позволяет избежать гонок.
Вызовы Priority и Assign позволяют программисту управлять тем, как и где нити выполняются в многопроцессорной системе. Планирование CPU выполняется на основе приоритетов, так что программист может определять, какие нити более важные, а какие - менее важные.
Активными объектами в Mach являются нити. Все нити процесса разделяют одно адресное пространство и имеют общие в пределах процесса ресурсы, показанные на рисунке 6.2. Кроме того, каждая нить имеет и свои особые ресурсы. Одним из таких ресурсов является порт нити, который является аналогом порта процесса и который используется нитью для того, чтобы вызывать специальные, ориентированные на нити, сервисы ядра, например, функцию завершения нити. Так как порты являются общими ресурсами для всех нитей одного процесса, каждая нить имеет доступ к портам своих нитей-братьев, таким образом каждая нить может управлять другой нитью, если это необходимо. Нити Mach управляются ядром, то есть они являются тем, что иногда называют "тяжеловесными" нитями, в отличие от "легковесных" нитей (нитей, полностью выполняющихся в пользовательском пространстве). Создание и уничтожение нитей осуществляется ядром и включает обновление структур данных ядра. Нити ядра предоставляют базовые механизмы для управления множеством "активностей" в общем адресном пространстве. Что делать с этими механизмами - это дело пользователя.
На однопроцессорной системе нити выполняются в режиме мультипрограммирования. На многопроцессорной системе нити выполняются параллельно. Этот параллелизм делает более важными вопросы синхронизации, взаимного исключения и планирования. Поскольку Mach ориентирована для выполнения на многопроцессорных системах, этим вопросам уделяется особое внимание. Подобно процессу, нить может быть активной или заблокированной. Механизм блокировки очень простой: просто у каждой нити есть счетчик, который наращивается или уменьшается. Когда он равен нулю - нить готова к выполнению. Когда он положителен, нить должна ждать, пока другая нить не уменьшит его до нуля. Такой механизм позволяет нитям управлять поведением друг друга. Имеется некоторое множество примитивов, связанных с нитями. Базовый интерфейс ядра обеспечивает примерно 2 десятка примитивов для нитей. Многие из них связаны с планированием. На базе этих примитивов можно строить различные пакеты нитей.
Мы уже рассматривали один пакет нитей в главе 4, а именно, пакет нитей DCE. Гораздо более скромные возможности предоставляет так называемый C-пакет нитей, поддерживаемый Mach (который был положен в основу пакета OSF). Этот пакет предназначен для того, чтобы дать возможность пользователям использовать нитевые примитивы ядра в простой и доступной форме. Он не предоставляет всю мощность, которую предлагает интерфейс ядра, однако он достаточен для реализации задач среднего уровня сложности. Этот пакет обладает свойством переносимости на широкий круг операционных систем и архитектур.
С-пакет содержит 6 вызовов, предназначенных для непосредственного манипулирования нитями. Эти вызовы приведены в таблице 6.2.
Таблица 6.2.
| Вызов | Описание | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fork | Создает новую нить, выполняющую тот же код, что и родительская нить | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Exit | Завершает нить | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Join | Приостанавливает вызывающую нить до тех пор, пока существует некоторая указанная нить | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Detach | Объявляет, что нить никогда не будет присоединена (ее не нужно ждать) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Yield | Отдает управление процессором по собственной инициативе | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Self | Возвращает нити ее идентификатор | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Первый вызов, Fork, создает новую нить в том же адресном пространстве, в котором работает вызывающая нить. Новая нить выполняет процедуру, указанную в качестве параметра вызова Fork, а не процедуру родительской нити. После выполнения вызова родительская нить продолжает выполняться параллельно с порожденной нитью. Нить запускается с приоритетом и назначается на процессор в соответствии с параметрами процесса, к которому она относится.
Когда нить завершает свою работу, она выполняет вызов Exit. Если родительская нить заинтересована фактом завершения данной нити и выполнила вызов Join, то родительская нить блокирует себя до тех пор, пока данная нить, порожденная ею, не завершится. Если эта нить уже завершилась, родительская нить немедленно продолжает свое выполнение. Эти три вызова является грубыми аналогами системных вызовов UNIX'а FORK, EXIT и WAITPID.
Четвертый вызов, Detach, в UNIX'е отсутствует. Он обеспечивает способ, с помощью которого какая-либо нить может объявить, что ее не следует ждать. Обычно очистка стека и другой информации о состоянии родительской нити происходит только после того, как эта нить, присоединившая нить-потомок с помощью вызова Join, будет уведомлена о завершении нити-потомка. Для нити, выполнившей вызов Detach, такая очистка происходит немедленно после ее завершения (с помощью вызова Exit). В сервере это может быть полезно, когда для обслуживания каждого поступающего запроса инициализируется новая нить, а не используется уже существующая.
Вызов Yield говорит планировщику о том, что у нити нет полезной работы в данный момент времени, и она отдает управление процессором по собственной инициативе. В Mach, где обычно используется вытесняющая многозадачность, вызов Yield используется только для оптимизации. В системах с невытесняющей многозадачностью этот вызов - основной для планирования работы нитей.
Синхронизация осуществляется с помощью мьютексов и переменных состояния. Примитивами мьютексов являются вызовы Lock, Trylock и Unlock. Также есть примитивы для распределения и освобождения мьютексов. Примитивы мьютексов в С-пакете те же, что и в пакете DCE.
Реализация С-нитей в Mach
В Mach существует несколько реализаций С-нитей. Оригинальная реализация выполняет все нити в пользовательском пространстве внутри одного процесса. Этот подход основан на разделении во времени всеми С-нитями одной нити ядра, как это показано на рисунке 6.3, а. Этот подход может также использоваться в UNIX'е или любой другой системе, в которой нет поддержки нитей ядром. Такие нити работают как разные подпрограммы одной программы, что означает, что они планируются невытесняющим образом. Например, в случае типовой задачи "производитель-покупатель" производитель должен заполнить буфер, а затем заблокироваться, чтобы дать шанс покупателю на выполнение.
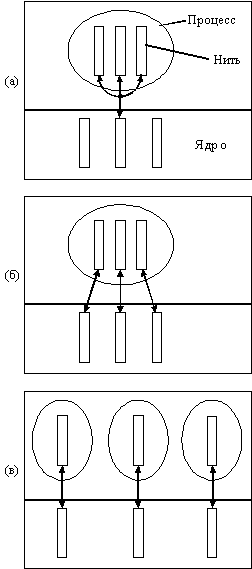
Рис. 6.3. Варианты реализаций С-нитей
(а) - Все C-нити используют одну нить ядра;
(б) - Каждая C-нить имеет свою собственную нить ядра;
(в) - Каждая C-нить имеет свой собственный однонитевый процесс
Данная реализация имеет недостаток, присущий всем нитевым пакетам, работающим в пользовательском пространстве без поддержки ядра. Если одна нить выполняет блокирующий системный вызов, например, чтение с терминала, то блокируется весь процесс. Чтобы избежать этой ситуации, программист должен избегать использовать блокирующие системные вызовы. В BSD UNIX имеется системный вызов SELECT, который может быть использован для того, чтобы узнать, имеется ли символ в буфере терминала. Но в целом операция остается запутанной.
Вторая реализация использует одну Mach-нить для одной С-нити, как показано на рисунке 6.3, б. Эти нити планируются с вытеснением. В многопроцессорных системах нити могут действительно работать параллельно на различных процессорах. Фактически возможно мультиплексирование m пользовательских нитей с n нитями ядра, хотя наиболее общим случаям является n=m.
В третьей реализации для каждого процесса выделяется одна нить ядра, как показано на рисунке 6.3, в. Процессы реализуются так, что их адресные пространства отображаются в одну и ту же физическую память, позволяя разделять ее тем же способом, что и в предыдущих реализациях. Данный способ поддержки нитей используется только тогда, когда требуется специализированное использование виртуальной памяти. Недостатком этого метода является то, что порты, UNIX-файлы и другие ресурсы процесса не могут разделяться.
Основное практическое значение первого подхода состоит в том, что в условиях отсутствия истинного параллелизма последовательное выполнение нити позволяет воспроизводить промежуточные результаты, облегчая процесс отладки.
Планирование в Mach в значительной степени определяется тем, что она предназначена для работы на многопроцессорных системах. Так как система с одним процессором является частным случаем многопроцессорной системы, мы сконцентрируем свое внимание на планировании в многопроцессорных системах.
Все процессоры многопроцессорной системы могут быть приписаны к некоторому набору процессоров. Каждый процессор относится точно к одному набору. Таким образом, каждый процессорный набор имеет в своем распоряжении несколько процессоров и несколько нитей, которые нуждаются в вычислительной мощности. В обязанности планирующего алгоритма входит работа по назначению нитей процессорам справедливым и эффективным образом. При планировании каждый процессорный набор представляется замкнутым миром со своими собственными ресурсами и со своими потребителями и является независимым от других процессорных наборов.
Такой механизм предоставляет процессам значительный контроль над своими нитями. Процесс может назначить важную нить процессорному набору, состоящему из одного процессора и не имеющему более ни одной прикрепленной нити, что гарантирует, что эта важная нить будет выполняться все время. Он может также динамически перераспределять нити между процессорными наборами во время их работы, балансируя нагрузку. В то время как средний компилятор обычно не использует этот механизм, система управления базами данных или система реального времени может его использовать.
Планирование нитей в Mach основано на приоритетах. Приоритеты - это целые числа от 0 до 31, причем 0 соответствует наивысшему приоритету, а 31 - самому низшему. Каждой нити присваиваются три значения, влияющих на его приоритет. Первое значение - базовый приоритет, который нить может назначить сама с определенными ограничениями. Второе число - это наименьшее числовое значение, которое может принять базовый приоритет. Третье значение - это текущий приоритет, используемый в целях планирования. Он вычисляется ядром путем прибавления к базовому приоритету значения функции, учитывающей использование процессора нитью в последнюю итерацию.
При использовании второй модели, в которой каждой нити пользователя соответствует одна нить ядра, ядро Mach видит С-нити. Каждая нить борется за процессорное время со всеми другими нитями, независимо от того, к какому процессу относится та или иная нить. С каждым процессорным набором связано 32 очереди готовых к выполнению нитей, по одной для каждого значения приоритета (рисунок 6.4). Совокупность этих 32 очередей называется глобальной очередью процессорного набора. С каждой глобальной очередью связано три переменных. Первая переменная - это мьютекс, который используется для блокирования структур данных глобальной очереди. Он используется для того, чтобы гарантировать, что с очередью в данный момент времени работает только один процессор. Вторая переменная является счетчиком количества нитей во всех 32 очередях. Третья переменная-ссылка содержит указание о том, где найти наиболее приоритетную нить. Она позволяет искать наиболее приоритетную нить, начиная с некоторого уровня, не просматривая все пустые очереди наверху.
Помимо глобальной очереди, каждый процессор имеет свою собственную локальную очередь, в которой находятся нити, постоянно приписанные к этому процессору, например, потому, что они являются драйверами устройств ввода-вывода, которые закреплены за этим процессором. Эти нити не стоит помещать в глобальную очередь, так как они могут выполняться только на одном определенном процессоре.
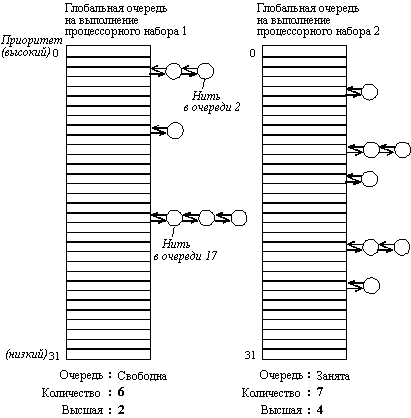
Рис. 6.4. Глобальные очереди на выполнение
для ситуации с двумя процессорными наборами
Основной алгоритм планирования заключается в следующем. Когда нить блокируется, завершается или исчерпывает свой квант, процессор, на котором она выполнялась, прежде всего просматривает свою локальную очередь, на предмет того, есть ли в ней какие-либо нити. Для этого анализируется счетчик нитей, связанный с этой очередью. Если он не равен 0, процессор начинает искать наиболее приоритетную нить, начиная с очереди, указанной в переменной-ссылке. Если локальная очередь пуста, такой же алгоритм применяется для глобальной очереди, с той разницей, что глобальная очередь должна быть заблокирована перед тем, как начать выполнять поиск. Если ни в одной очереди нет готовых нитей, то запускается и выполняется специальная нить для простоев до тех пор, пока не появится какая-нибудь готовая нить.
Если готовая нить обнаружена, то она получает возможность выполняться в течение одного кванта. По завершении кванта, обе очереди - локальная и глобальная - просматриваются, чтобы узнать, нет ли еще нитей с таким же или более высоким приоритетом, с учетом того, что все нити из локальной очереди имеют более высокий приоритет, чем нити в глобальной очереди. Если подходящий кандидат найден, то происходит переключение нити. Если нет, то активная нить выполняется еще в течение одного кванта. Нить может быть также вытеснена. На многопроцессорной системе длина кванта может быть переменной, в зависимости от числа нитей, которые готовы к выполнению. Увеличение числа готовых нитей и уменьшение числа процессоров укорачивает квант. Такой алгоритм дает хорошее время ответа для коротких запросов, даже если система сильно загружена, и обеспечивает высокую эффективность (длинный квант) для мало загруженных систем.
При каждом тике таймера процессор наращивает приоритетный счетчик текущей нити на небольшую величину. Чем больше становится значение приоритета, тем ниже приоритет нити, и нить в конце концов перемещается в очередь с самым большим номером, то есть с самым низким приоритетом.
В некоторых приложениях над решением одной проблемы работает большое количество нитей, поэтому для них важно иметь возможность управлять планированием в деталях. Mach предоставляет нитям дополнительное средство управления планированием (кроме процессорных наборов и приоритетов). Таким средством является системный вызов, который позволяет нити снижать свой приоритет до абсолютного минимума в течение указанного количества секунд. Это дает возможность выполняться другим нитям. После того как указанный интервал истечет, приоритету возвращается его прежнее значение.
Этот системный вызов имеет другое интересное свойство: он может назвать своего наследника, если захочет. Например, после отсылки сообщения другой нити посылающая нить освобождает процессор и требует, чтобы следующей выполнялась нить-получатель. Этот механизм, называемый планированием с передачами, минует все очереди. Если его использовать с умом, то можно повысить производительность. Ядро также использует этот механизм при некоторых обстоятельствах в качестве оптимизации.
Ядро Mach может быть сконфигурировано так, чтобы реализовывать так называемое аффинное планирование, но обычно такая опция не устанавливается. Когда она установлена, ядро планирует нить на процессор, на котором эта нить последний раз выполнялась в надежде на то, что часть ее адресного пространства все еще сохранилась в кэше данного процессора. Аффинное планирование применимо только для многопроцессорных систем.