 |
Сервер поддерживается Центром Информационных Технологий (095) 932-9212, 932-9213, 939-0783 E-mail: info@citforum.ru |
|
Сервер Информационных Технологий содержит море(!) аналитической информации
|
|
|---|---|
|
Сервер поддерживается Центром Информационных Технологий (095) 932-9212, 932-9213, 939-0783 E-mail: info@citforum.ru |
|
Сервер Информационных Технологий содержит море(!) аналитической информации
|
|
|---|---|
В предыдущей главе мы рассмотрели средства конвейеризации, которые обеспечивают совмещенный режим выполнения команд, когда они являются независимыми друг от друга. Это потенциальное совмещение выполнения команд называется параллелизмом на уровне команд. В данной главе мы рассмотрим ряд методов развития идей конвейеризации, основанных на увеличении степени параллелизма, используемой при выполнении команд. Мы начнем с рассмотрения методов, позволяющих снизить влияние конфликтов по данным и по управлению, а затем вернемся к теме расширения возможностей процессора по использованию параллелизма, заложенного в программах. Затем мы обсудим современные технологии компиляторов, используемые для увеличения степени параллелизма уровня команд.
Для начала запишем выражение, определяющее среднее количество тактов для выполнения команды в конвейере:
CPI конвейера = CPI идеального конвейера +
+ Приостановки из-за структурных конфликтов +
+ Приостановки из-за конфликтов типа RAW +
+ Приостановки из-за конфликтов типа WAR +
+ Приостановки из-за конфликтов типа WAW +
+ Приостановки из-за конфликтов по управлению
CPI идеального конвейера есть не что иное, как максимальная пропускная способность, достижимая при реализации. Уменьшая каждое из слагаемых в правой части выражения, мы минимизируем общий CPI конвейера и таким образом увеличиваем пропускную способность команд. Это выражение позволяет также охарактеризовать различные методы, которые будут рассмотрены в этой главе, по тому компоненту общего CPI, который соответствующий метод уменьшает. На рис. 6.1 показаны некоторые методы, которые будут рассмотрены, и их воздействие на величину CPI.
Прежде, чем начать рассмотрение этих методов, необходимо определить концепции, на которых эти методы построены.
Параллелизм уровня команд: зависимости и конфликты по данным
Все рассматриваемые в этой главе методы используют параллелизм, заложенный в последовательности команд. Как мы установили выше этот тип параллелизма называется параллелизмом уровня команд или ILP. Степень параллелизма, доступная внутри базового блока (линейной последовательности команд, переходы из вне которой разрешены только на ее вход, а переходы внутри которой разрешены только на ее выход) достаточно мала. Например, средняя частота переходов в целочисленных программах составляет около 16%. Это означает, что в среднем между двумя переходами выполняются примерно пять команд. Поскольку эти пять команд возможно взаимозависимые, то степень перекрытия, которую мы можем использовать внутри базового блока, возможно будет меньше чем пять. Чтобы получить существенное улучшение производительности, мы должны использовать параллелизм уровня команд одновременно для нескольких базовых блоков.
| Метод | Снижает | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Разворачивание циклов | Приостановки по управлению | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Базовое планирование конвейера | Приостановки RAW | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Динамической планирование с централизованной схемой управления | Приостановки RAW | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Динамическое планирование с переименованием регистров | Приостановки WAR и WAW | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Динамическое прогнозирование переходов | Приостановки по управлению | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Выдача нескольких команд в одном такте | Идеальный CPI | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Анализ зависимостей компилятором | Идеальный CPI и приостановки по данным | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Программная конвейеризация и планирование трасс | Идеальный CPI и приостановки по данным | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Выполнение по предположению | Все приостановки по данным и управлению | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Динамическое устранение неоднозначности памяти | Приостановки RAW, связанные с памятью | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.1.
Самый простой и общий способ увеличения степени параллелизма, доступного на уровне команд, является использование параллелизма между итерациями цикла. Этот тип параллелизма часто называется параллелизмом уровня итеративного цикла. Ниже приведен простой пример цикла, выполняющего сложение двух 1000-элементных векторов, который является полностью параллельным:
for (i = 1; i <= 1000; i = i + 1)
x[i] = x[i] + y[i];
Каждая итерация цикла может перекрываться с любой другой итерацией, хотя внутри каждой итерации цикла практическая возможность перекрытия небольшая.
Имеется несколько методов для превращения такого параллелизма уровня цикла в параллелизм уровня команд. Эти методы основаны главным образом на разворачивании цикла либо статически, используя компилятор, либо динамически с помощью аппаратуры. Ниже в этом разделе мы рассмотрим подробный пример разворачивания цикла.
Важным альтернативным методом использования параллелизма уровня команд является использование векторных команд. По существу векторная команда оперирует с последовательностью элементов данных. Например, приведенная выше последовательность на типичной векторной машине может быть выполнена с помощью четырех команд: двух команд загрузки векторов x и y из памяти, одной команды сложения двух векторов и одной команды записи вектора-результата. Конечно, эти команды могут быть конвейеризованными и иметь относительно большие задержки выполнения, но эти задержки могут перекрываться. Векторные команды и векторные машины заслуживают отдельного рассмотрения, которое выходит за рамки данного курса. Хотя разработка идей векторной обработки предшествовала появлению большинства методов использования параллелизма, которые рассматриваются в этой главе, машины, использующие параллелизм уровня команд постепенно заменяют машины, базирующиеся на векторной обработке. Причины этого сдвига технологии обсуждаются более детально позже в данном курсе.
Зависимости
Чтобы точно определить, что мы понимаем под параллелизмом уровня цикла и параллелизмом уровня команд, а также для количественного определения степени доступного параллелизма, мы должны определить, что такое параллельные команды и параллельные циклы. Начнем с объяснения того, что такое пара параллельных команд. Две команды являются параллельными, если они могут выполняться в конвейере одновременно без приостановок, предполагая, что конвейер имеет достаточно ресурсов (структурные конфликты отсутствуют).
Поэтому, если между двумя командами существует взаимозависимость, то они не являются параллельными. Имеется три типа зависимостей: зависимости по данным, зависимости по именам и зависимости по управлению. Команда j зависит по данным от команды i, если имеет место любое из следующих условий:
Второе условие просто означает, что одна команда зависит от другой, если между этими двумя командами имеется цепочка зависимостей первого типа. Эта цепочка зависимостей может быть длиною во всю программу.
Если две команды являются зависимыми по данным, они не могут выполняться одновременно или полностью совмещено. Зависимость по данным предполагает, что между двумя командами имеется цепочка из одного или нескольких конфликтов типа RAW. Одновременное выполнение таких команд требует создания машины с внутренними схемами блокировок конвейера, обеспечивающих обнаружение конфликтов и уменьшение времени приостановок или полное устранение перекрытия. В машине без внутренних блокировок, которые базируются на программном планировании работы конвейера компилятором, компилятор не может спланировать зависимые команды так, чтобы они полностью совмещались, поскольку в противном случае программа не будет выполняться правильно. Наличие зависимостей по данным в последовательности команд отражает зависимость по данным в исходном тексте программы, на основании которого она генерировалась. Эффект первоначальной зависимости по данным должен сохраняться.
Зависимости являются свойством программ. Приведет ли данная зависимость к обнаруживаемому конфликту и вызовет ли данный конфликт реальную приостановку конвейера, зависит от организации конвейера. Действительно, многие методы, рассматриваемые в этой главе, позволяют обойти конфликты или обойти необходимость приостановки конвейера в случае возникновения конфликта, при сохранении зависимости. Важность зависимостей по данным заключается в том, что именно они устанавливают верхнюю границу степени параллелизма, который вероятно может быть использован. Наличие зависимостей по данным означает также, что результаты должны вычисляться в определенном порядке, поскольку более поздняя команда зависит от результата предыдущей.
Данные могут передаваться от команды к команде либо через регистры, либо через ячейки памяти. Когда данные передаются через регистры, обнаружение зависимостей значительно упрощается, поскольку имена регистров зафиксированы в командах (хотя этот процесс становится более сложным, если вмешиваются условные переходы). Зависимости по данным, которые передаются через ячейки памяти, обнаружить значительно сложнее, поскольку два адреса могут относиться к одной и той же ячейке памяти, но внешне выглядят по разному (например, 100(R4) и 20(R6) могут определять один и тот же адрес). Кроме того, эффективный адрес команды загрузки или записи может меняться от одного выполнения команды к другому (так что 20(R4) и 20(R4) будут определять разные адреса), еще больше усложняя обнаружение зависимости. В этой главе мы рассмотрим как аппаратные, так и программные методы обнаружения зависимостей по данным, которые связаны с ячейками памяти. Методы компиляции для обнаружения таких зависимостей являются очень важными при выявлении параллелизма уровня
цикла.
Вторым типом зависимостей в программах являются зависимости по именам. Зависимости по именам возникают когда две команды используют одно и то же имя (либо регистра, либо ячейки памяти), но при отсутствии передачи данных между командами. Имеется два типа зависимости имен между командой i, которая предшествует команде j в программе:
Как антизависимости, так и зависимости по выходу являются зависимостями по именам, в отличие от истинных зависимостей по данным, поскольку в них отсутствует передача данных от одной команды к другой. Это означает, что команды, связанные зависимостью по именам, могут выполняться одновременно или могут быть переупорядочены, если имя (номер регистра или адрес ячейки памяти), используемое в командах изменяется так, что команды не конфликтуют. Это переименование может быть выполнено более просто для регистровых операндов и называется переименованием регистров (register renaming). Переименование регистров может выполняться либо статически компилятором, или динамически аппаратными средствами.
В качестве примера рассмотрим следующую последовательность команд:
ADD R1,R2,R3
SUB R2,R3,R4
AND R5,R1,R2
OR R1,R3,R4
В этой последовательности имеется антизависимость по регистру R2 между командами ADD и SUB, которая может привести к конфликту типа WAR. Ее можно устранить путем переименования регистра результата команды SUB, например, на R6 и изменения всех последующих команд, которые используют результат команды вычитания, для использования этого регистра R6 (в данном случае это только последний операнд в команде AND). Использование R1 в команде OR приводит как к зависимости по выходу с командой ADD, так и к антизависимости между командами ADD и AND. Обе зависимости могут быть устранены путем замены регистра результата либо команды ADD, либо команды OR. В первом случае должна измениться каждая команда, которая использует результат команды ADD прежде чем команда OR запишет в регистр R1 (а именно, второй операнд команды AND в данном примере). Во втором случае при замене регистра результата команды OR, все последующие команды, использующие ее результат, должны также измениться. Альтернативой переименованию в процессе компиляции является аппаратное переименование регистров, которое может быть использовано в ситуациях, когда возникают условные переходы, которые возможно сложны или невозможны для анализа компилятором; в следующем разделе эта методика обсуждается более подробно.
Последним типом зависимостей являются зависимости по управлению. Зависимости по управлению определяют порядок команд по отношению к команде условного перехода так, что команды, не являющиеся командами перехода, выполняются только когда они должны выполняться. Каждая команда в программе является зависимой по управлению от некоторого набора условных переходов и, в общем случае, эти зависимости по управлению должны сохраняться. Одним из наиболее простых примеров зависимости по управлению является зависимость операторов, находящихся в части "then" оператора условного перехода if. Например, в последовательности кода:
if p1 {
S1;
};
if p2 {
S2;
}
S1 является зависимым по управлению от p1, а S2 зависит по управлению от p2 и не зависит от p1.
Имеются два ограничения, связанные с зависимостями по управлению:
Следующий пример иллюстрирует эти два ограничения:
ADD R1,R2,R3
BEQZ R12,skipnext
SUB R4,R5,R6
skipnext: OR R7,R1,R9
MULT R13,R1,R4
В этой последовательности команд имеются следующие зависимости по управлению (предполагается, что переходы не задерживаются). Команда SUB зависит по управлению от команды BEQZ, поскольку изменение порядка следования этих команд изменит и результат вычислений. Если поставить команду SUB перед командой условного перехода, результат команды MULT не будет тем же самым, что и в случае, когда условный переход является выполняемым. Аналогично, команда ADD не может быть поставлена после команды условного перехода, поскольку это приведет к изменению результата команды MULT, когда переход является выполняемым. Команда OR не является зависимой по управлению от условного перехода, поскольку она выполняется независимо от того, является ли переход выполняемым или нет. Поскольку команда OR не зависит по данным от предшествующих команд и не зависит по управлению от команды условного перехода, она может быть поставлена перед командой условного перехода, что не приведет к изменению значения, вычисляемого этой последовательностью команд. Конечно это предполагает, что команда OR не вызывает никаких побочных эффектов (например, возникновения исключительной ситуации). Если мы хотим переупорядочить команды с подобными потенциальными побочными эффектами, требуется дополнительный анализ компилятором или дополнительная аппаратная поддержка.
Обычно зависимости по управлению сохраняются посредством двух свойств простых конвейеров, подобных рассмотренным в предыдущей главе. Во-первых, команды выполняются в порядке, предписанном программой. Это гарантирует, что команда, стоящая перед командой условного перехода, выполняется перед переходом; таким образом, команда ADD в выше приведенной последовательности будет выполняться перед условным переходом. Во-вторых, средства обнаружения конфликтов по управлению или конфликтов условных переходов гарантируют, что команда, зависимая по управлению от условного перехода, не будет выполняться до тех пор, пока не известно направление условного перехода. В частности команда SUB не будет выполняться до тех пор, пока машина не определит, что условный переход является невыполняемым.
Хотя сохранение зависимостей по управлению является полезным и простым способом обеспечения корректности программы, сама по себе зависимость по управлению не является фундаментальным ограничением производительности. Возможно мы были бы рады выполнять команды, которые не должны выполняться, тем самым нарушая зависимости по управлению, если бы могли это делать не нарушая корректность программы. Зависимость по управлению не является критическим свойством, которое должно сохраняться. В действительности, двумя свойствами, которые являются критичными с точки зрения корректности программы и которые обычно сохраняются посредством зависимостей по управлению, являются поведение исключительных ситуаций (exception behavior) и поток данных (data flow).
Сохранение поведения исключительных ситуаций означает, что любые изменения в порядке выполнения команд не должны менять условия возникновения исключительных ситуаций в программе. Часто это требование можно смягчить: переупорядочивание выполнения команд не должно приводить к появлению в программе новых исключительных ситуаций. Простой пример показывает как поддержка зависимостей по управлению может сохранить эти ситуации. Рассмотрим кодовую последовательность:
BEQZ R2,L1
LW R1,0(R2)
L1:
В данном случае, если мы игнорируем зависимость по управлению и ставим команду загрузки перед командой условного перехода, команда загрузки может вызвать исключительную ситуацию по защите памяти. Заметим, что здесь зависимость по данным, которая препятствует перестановке команд BEQZ и LW, отсутствует, это только зависимость по управлению. Подобная ситуация может возникнуть и при выполнении операции с ПТ, которая может вызвать исключительную ситуацию. В любом случае, если переход выполняется, то исключительная ситуация не возникнет, если команда не ставится выше команды условного перехода. Чтобы разрешить переупорядочивание команд мы хотели бы как раз игнорировать исключительную ситуацию, если переход не выполняется. В разд. 6.7 мы рассмотрим два метода, выполнение по предположению и условные команды, которые позволяют нам справиться с этой проблемой.
Вторым свойством, сохраняемым с помощью поддержки зависимостей по управлению, является поток данных. Поток данных представляет собой действительный поток данных между командами, которые вырабатывают результаты, и командами, которые эти результаты используют. Условные переходы делают поток данных динамическим, поскольку они позволяют данным для конкретной команды поступать из многих точек (источников). Рассмотрим следующую последовательность команд:
ADD R1,R2,R3
BEQZ R4,L
SUB R1,R5,R6
L: OR R7,R1,R8
В этом примере значение R1, используемое командой OR, зависит от того, выполняется или не выполняется условный переход. Одной зависимости по данным не достаточно для сохранения корректности программы, поскольку она имеет дело только со статическим порядком чтения и записи. Таким образом, хотя команда OR зависит по данным как от команды ADD, так и от команды SUB, этого недостаточно для корректного выполнения. Когда выполняются команды, должен сохраняться поток данных: если переход не выполняется, то команда OR должна использовать значение R1, вычисленное командой SUB, а если переход выполняется - значение R1, вычисленное командой ADD. Перестановка команды SUB на место перед командой условного перехода не меняет статической зависимости, но она определенно повлияет на поток данных и таким образом приведет к некорректному выполнению. При сохранении зависимости по управлению команды SUB от условного перехода, мы предотвращаем незаконное изменение потока данных. Выполнение команд по предположению и условные команды, которые помогают решить проблему исключительных ситуаций, позволяют также изменить зависимость по управлению, поддерживая при этом правильный поток данных (разд. 6.7).
Иногда мы можем определить, что устранение зависимости по управлению, не может повлиять на поведение исключительных ситуаций, либо на поток данных. Рассмотрим слегка модифицированную последовательность команд:
ADD R1,R2,R3
BEQZ R12,skipnext
SUB R4,R5,R6
ADD R5,R4,R9
skipnext: OR R7,R8,R9
Предположим, что мы знаем, что регистр результата команды SUB (R4) не используется после команды, помеченной меткой skipnext. (Свойство, определяющее, будет ли значение использоваться последующими командами, называется живучестью (liveness) и мы вскоре определим его более формально). Если бы регистр R4 не использовался, то изменение значения R4 прямо перед выполнением условного перехода не повлияло бы на поток данных. Таким образом, если бы регистр R4 не использовался и команда SUB не могла выработать исключительную ситуацию, мы могли бы поместить команду SUB на место перед командой условного перехода, поскольку на результат программы это изменение не влияет. Если переход выполняется, команда SUB выполнится и будет бесполезна, но она не повлияет на результат программы. Этот тип планирования кода иногда называется планированием по предположению (speculation), поскольку компилятор в основном делает ставку на исход условного перехода; в данном случае предполагается, что условный переход обычно является невыполняемым. Более амбициозные механизмы планирования по предположению в компиляторах обсуждаются в разд. 6.7.
Механизмы задержанных переходов, которые мы рассматривали в предыдущей главе, могут использоваться для уменьшения простоев, возникающих по вине условных переходов, и иногда позволяют использовать планирование по предположению для оптимизации задержек переходов.
Зависимости по управлению сохраняются путем реализации схемы обнаружения конфликта по управлению, которая приводит к приостановке конвейера по управлению. Приостановки по управлению могут устраняться или уменьшаться множеством аппаратных и программных методов. Например, задержанные переходы могут уменьшать приостановки, возникающие в результате конфликтов по управлению. Другие методы уменьшения приостановок, вызванных конфликтами по управлению включают разворачивание циклов, преобразование условных переходов в условно выполняемые команды и планирование по предположению, выполняемое с помощью компилятора или аппаратуры. В данной главе будут рассмотрены большинство этих методов.
Параллелизм уровня цикла: концепции и методы
Параллелизм уровня цикла обычно анализируется на уровне исходного текста программы или близкого к нему, в то время как анализ параллелизма уровня команд главным образом выполняется, когда команды уже сгенерированы компилятором. Анализ на уровне циклов включает определение того, какие зависимости существуют между операндами в цикле в пределах одной итерации цикла. Теперь мы будем рассматривать только зависимости по данным, которые возникают, когда операнд записывается в некоторой точке и считывается в некоторой более поздней точке. Мы обсудим коротко зависимости по именам. Анализ параллелизма уровня цикла фокусируется на определении того, зависят ли по данным обращения к данным в последующей итерации от значений данных, вырабатываемых в более ранней итерации.
Рассмотрим следующий цикл:
for (i=1; i<=100; i=i+1) {
A[i+1] = A[i] + C[i]; /* S1 */
B[i+1] = B[i] + A[i+1];} /*S2*/
}
Предположим, что A, B и C представляют собой отдельные, неперекрывающиеся массивы. (На практике иногда массивы могут быть теми же самыми или перекрываться. Поскольку массивы могут передаваться в качестве параметров некоторой процедуре, которая содержит этот цикл, определение того, перекрываются ли массивы или они совпадают, требует изощренного, межпроцедурного анализа программы). Какие зависимости по данным имеют место между операторами этого цикла?
Имеются две различных зависимости:
Эти две зависимости отличаются друг от друга и имеют различный эффект. Чтобы увидеть, чем они отличаются, предположим, что в каждый момент времени существует только одна из этих зависимостей. Рассмотрим зависимость оператора S1 от более ранней итерации S1. Эта зависимость (loop-carried dependence) означает, что между различными итерациями цикла существует зависимость по данным. Более того, поскольку оператор S1 зависит от самого себя, последовательные итерации оператора S1 должны выполняться упорядочено.
Вторая зависимость (S2 зависит от S1) не передается от итерации к итерации. Таким образом, если бы это была единственная зависимость, несколько итераций цикла могли бы выполняться параллельно, при условии, что каждая пара операторов в итерации поддерживается в заданном порядке.
Имеется третий тип зависимостей по данным, который возникает в циклах, как показано в следующем примере.
Рассмотрим цикл:
for (i=1; i<=100; i=i+1) {
A[i] = A[i] + B[i]; /* S1 */
B[i+1] = C[i] + D[i]; /* S2 */
}
Оператор S1 использует значение, которое присваивается оператором S2 в предыдущей итерации, так что имеет место зависимость между S2 и S1 между итерациями.
Несмотря на эту зависимость, этот цикл может быть сделан параллельным. Как и в более раннем цикле эта зависимость не циклическая: ни один из операторов не зависит сам от себя и хотя S1 зависит от S2, S2 не зависит от S1. Цикл является параллельным, если только отсутствует циклическая зависимость.
Хотя в вышеприведенном цикле отсутствуют циклические зависимости, чтобы выявить параллелизм, он должен быть преобразован в другую структуру. Здесь следует сделать два важных замечания:
Эти два замечания позволяют нам заменить выше приведенный цикл следующей последовательностью:
A[1] = A[1] + B[1];
for (i=1; i<=99; i=i+1) {
B[i+1] = C[i] + D[i];
A[i+1] = A[i+1] + B[i+1];
}
B[101] = C[100] + D[100];
Теперь итерации цикла могут выполняться с перекрытием, при условии, что операторы в каждой итерации выполняются в заданном порядке. Имеется множество такого рода преобразований, которые реструктурируют цикл для выявления параллелизма.
Основное внимание в оставшейся части этой главы сосредоточено на методах выявления параллелизма уровня команд. Зависимости по данным в откомпилированных программах представляют собой ограничения, которые оказывают влияние на то, какая степень параллелизма может быть использована. Вопрос заключается в том, чтобы подойти к этому пределу путем минимизации действительных конфликтов и связанных с ними приостановок конвейера. Методы, которые мы изучаем становятся все более изощренными в стремлении использования всего доступного параллелизма при поддержании истинных зависимостей по данным в коде программы. Как компилятор, так и аппаратура здесь играют свою роль: компилятор старается устранить или минимизировать зависимости, в то время как аппаратура старается предотвратить превращение зависимостей в приостановки конвейера.
Основы планирования загрузки конвейера и разворачивание циклов
Для поддержания максимальной загрузки конвейера должен использоваться параллелизм уровня команд, основанный на выявлении последовательностей несвязанных команд, которые могут выполняться в конвейере с совмещением. Чтобы избежать приостановки конвейера зависимая команда должна быть отделена от исходной команды на расстояние в тактах, равное задержке конвейера для этой исходной команды. Способность компилятора выполнять подобное планирование зависит как от степени параллелизма уровня команд, доступного в программе, так и от задержки функциональных устройств в конвейере. В рамках этой главы мы будем предполагать задержки, показанные на рис. 6.2, если только явно не установлены другие задержки. Мы предполагаем, что условные переходы имеют задержку в один такт, так что команда следующая за командой перехода не может быть определена в течение одного такта после команды условного перехода. Мы предполагаем, что функциональные устройства полностью конвейеризованы или дублированы (столько раз, какова глубина конвейера), так что операция любого типа может выдаваться для выполнения в каждом такте и структурные конфликты отсутствуют.
| Команда, вырабатывающая результат | Команда, использующая результат | Задержка в тактах | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Операция АЛУ с ПТ | Другая операция АЛУ с ПТ | 3 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Операция АЛУ с ПТ | Запись двойного слова | 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Загрузка двойного слова | Другая операция АЛУ с ПТ | 1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Загрузка двойного слова | Запись двойного слова | 0 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.2.
В данном коротком разделе мы рассмотрим вопрос о том, каким образом компилятор может увеличить степень параллелизма уровня команд путем разворачивания циклов. Для иллюстрации этих методов мы будем использовать простой цикл, который добавляет скалярную величину к вектору в памяти; это параллельный цикл, поскольку зависимость между итерациями цикла отсутствует. Мы предполагаем, что первоначально в регистре R1 находится адрес последнего элемента вектора (например, элемент с наибольшим адресом), а в регистре F2 - скалярная величина, которая должна добавляться к каждому элементу вектора. Программа для машины, не рассчитанная на использование конвейера, будет выглядеть примерно так:
Loop: LD F0,0(R1) ;F0=элемент вектора
ADDD F4,F0,F2 ;добавляет скаляр из F2
SD 0(R1),F4 ;запись результата
SUBI R1,R1,#8 ;пересчитать указатель
;8 байт (в двойном слове)
BNEZ R1, Loop ;переход R1!=нулю
Для упрощения мы предполагаем, что массив начинается с ячейки 0. Если бы он находился в любом другом месте, цикл потребовал бы наличия одной дополнительной целочисленной команды для выполнения сравнения с регистром R1.
Рассмотрим работу этого цикла при выполнении на простом конвейере с задержками, показанными на рис. 6.2.
Если не делать никакого планирования, работа цикла будет выглядеть следующим образом:
Такт выдачи
Loop: LD F0,0(R1) 1
приостановка 2
ADDD F4,F0,F2 3
приостановка 4
приостановка 5
SD 0(R1),F4 6
SUBI R1,R1,#8 7
BNEZ R1,Loop 8
приостановка 9
Для его выполнения потребуется 9 тактов на итерацию: одна приостановка для команды LD, две для команды ADDD, и одна для задержанного перехода. Мы можем спланировать цикл так, чтобы получить
Loop: LD F0,0(R1) 1
приостановка 2
ADDD F4,F0,F2 3
SUBI R1,R1,#8 4
BNEZ R1,Loop ;задержанный переход 5
SD 8(R1),F4 ;команда изменяется, когда 6
;меняется местами с командой SUB1
Время выполнения уменьшилось с 9 до 6 тактов.
Заметим, что для планирования задержанного перехода компилятор должен определить, что он может поменять местами команды SUB1 и SD путем изменения адреса в команде записи SD: Адрес был равен 0(R1), а теперь равен 8(R1). Это не тривиальная задача, поскольку большинство компиляторов будут видеть, что команда SD зависит от SUB1, и откажутся от такой перестановки мест. Более изощренный компилятор смог бы рассчитать отношения и выполнить перестановку. Цепочка зависимостей от команды LD к команде ADDD и далее к команде SD определяет количество тактов, необходимое для данного цикла.
В вышеприведенном примере мы завершаем одну итерацию цикла и выполняем запись одного элемента вектора каждые 6 тактов, но действительная работа по обработке элемента вектора отнимает только 3 из этих 6 тактов (загрузка, сложение и запись). Оставшиеся 3 такта составляют накладные расходы на выполнение цикла (команды SUB1, BNEZ и приостановка). Чтобы устранить эти три такта нам нужно иметь больше операций в цикле относительно числа команд, связанных с накладными расходами. Одним из наиболее простых методов увеличения числа команд по отношению к команде условного перехода и команд, связанных с накладными расходами, является разворачивание цикла. Такое разворачивание выполняется путем многократной репликации (повторения) тела цикла и коррекции соответствующего кода конца цикла.
Разворачивание циклов может также использоваться для улучшения планирования. В этом случае, мы можем устранить приостановку, связанную с задержкой команды загрузки путем создания дополнительных независимых команд в теле цикла. Затем компилятор может планировать эти команды для помещения в слот задержки команды загрузки. Если при разворачивании цикла мы просто реплицируем команды, то результирующие зависимости по именам могут помешать нам эффективно спланировать цикл. Таким образом, для разных итераций хотелось бы использовать различные регистры, что увеличивает требуемое число регистров.
Представим теперь этот цикл развернутым так, что имеется четыре копии тела цикла, предполагая, что R1 первоначально кратен 4. Устраним при этом любые очевидные излишние вычисления и не будем пользоваться повторно никакими регистрами.
Ниже приведен результат, полученный путем слияния команд SUB1 и выбрасывания ненужных операций BNEZ, которые дублируются при разворачивании цикла.
Loop: LD F0,0(R1)
ADDD F4,F0,F2
SD 0(R1),F4 ;выбрасывается SUB1 и BNEZ
LD F6,-8(R1)
ADDD F8,F6,F2
SD -8(R1),F8 ;выбрасывается SUB1 и BNEZ
LD F10,-16(R1)
ADDD F12,F10,F2
SD -16(R1),F12 ;выбрасывается SUB1 и BNEZ
LD F14,-24(R1)
ADDD F16,F14,F2
SD -24(R1),F16
SUB1 R1,R1,#32
BNEZ R1, Loop
Мы ликвидировали три условных перехода и три операции декрементирования R1. Адреса команд загрузки и записи были скорректированы так, чтобы позволить слить команды SUB1 в одну команду по регистру R1. При отсутствии планирования за каждой командой здесь следует зависимая команда и это будет приводить к приостановкам конвейера. Этот цикл будет выполняться за 27 тактов (на каждую команду LD потребуется 2 такта, на каждую команду ADDD - 3, на условный переход - 2 и на все другие команды 1 такт) или по 6.8 такта на каждый из четырех элементов. Хотя эта развернутая версия в такой редакции медленнее, чем оптимизированная версия исходного цикла, после оптимизации самого развернутого цикла ситуация изменится. Обычно разворачивание циклов выполняется на более ранних стадиях процесса компиляции, так что избыточные вычисления могут быть выявлены и устранены оптимизатором.
В реальных программах мы обычно не знаем верхней границы цикла. Предположим, что она равна n и мы хотели бы развернуть цикл так, чтобы иметь k копий тела цикла. Вместо единственного развернутого цикла мы генерируем пару циклов. Первый из них выполняется (n mod k) раз и имеет тело первоначального цикла. Развернутая версия цикла окружается внешним циклом, который выполняется (n div k) раз.
В вышеприведенном примере разворачивание цикла увеличивает производительность этого цикла путем устранения команд, связанных с накладными расходами цикла, хотя оно заметно увеличивает размер программного кода. Насколько увеличится производительность, если цикл будет оптимизироваться?
Ниже представлен развернутый цикл из предыдущего примера после оптимизации.
Loop: LD F0,0(R1)
LD F6,-8(R1)
LD F10,-16(R1)
LD F14,-24(R1)
ADDD F4,F0,F2
ADDD F8,F6,F2
ADDD F12,F10,F2
ADDD F16,F14,F2
SD 0(R1),F4
SD -8(R1),F8
SD -16(R1),F12
SUB1 R1,R1,#32
BNEZ R1, Loop
SD 8(R1),F16 ; 8 - 32 = -24
Время выполнения развернутого цикла снизилось до 14 тактов или до 3.5 тактов на элемент, по сравнению с 6.8 тактов на элемент до оптимизации, и по сравнению с 6 тактами при оптимизации без разворачивания цикла.
Выигрыш от оптимизации развернутого цикла даже больше, чем от оптимизации первоначального цикла. Это произошло потому, что разворачивание цикла выявило больше вычислений, которые могут быть оптимизированы для минимизации приостановок конвейера; приведенный выше программный код выполняется без приостановок. При подобной оптимизации цикла необходимо осознавать, что команды загрузки и записи являются независимыми и могут чередоваться. Анализ зависимостей по данным позволяет нам определить, являются ли команды загрузки и записи независимыми.
Разворачивание циклов представляет собой простой, но полезный метод увеличения размера линейного кодового фрагмента, который может эффективно оптимизироваться. Это преобразование полезно на множестве машин от простых конвейеров, подобных рассмотренному ранее, до суперскалярных конвейеров, которые обеспечивают выдачу для выполнения более одной команды в такте. В следующем разделе рассмотрены методы, которые используются аппаратными средствами для динамического планирования загрузки конвейера и сокращения приостановок из-за конфликтов типа RAW, аналогичные рассмотренным выше методам компиляции.
Основная идея динамической оптимизации
Главным ограничением методов конвейерной обработки, которые мы рассматривали ранее, является выдача для выполнения команд строго в порядке, предписанном программой: если выполнение какой-либо команды в конвейере приостанавливалось, следующие за ней команды также приостанавливались. Таким образом, при наличии зависимости между двумя близко расположенными в конвейере командами возникала приостановка обработки многих команд. Но если имеется несколько функциональных устройств, многие из них могут оказаться незагруженными. Если команда j зависит от длинной команды i, выполняющейся в конвейере, то все команды, следующие за командой j должны приостановиться до тех пор, пока команда i не завершится и не начнет выполняться команда j. Например, рассмотрим следующую последовательность команд:
DIVD F0,F2,F4
ADDD F10,F0,F8
SUBD F8,F8,F14
Команда SUBD не может выполняться из-за того, что зависимость между командами DIVD и ADDD привела к приостановке конвейера. Однако команда SUBD не имеет никаких зависимостей от команд в конвейере. Это ограничение производительности, которое может быть устранено снятием требования о выполнении команд в строгом порядке.
В рассмотренном нами конвейере структурные конфликты и конфликты по данным проверялись во время стадии декодирования команды (ID). Если команда могла нормально выполняться, она выдавалась с этой ступени конвейера в следующие. Чтобы позволить начать выполнение команды SUBD из предыдущего примера, необходимо разделить процесс выдачи на две части: проверку наличия структурных конфликтов и ожидание отсутствия конфликта по данным. Когда мы выдаем команду для выполнения, мы можем осуществлять проверку наличия структурных конфликтов; таким образом, мы все еще используем упорядоченную выдачу команд. Однако мы хотим начать выполнение команды как только станут доступными ее операнды. Таким образом, конвейер будет осуществлять неупорядоченное выполнение команд, которое означает и неупорядоченное завершение команд.
Неупорядоченное завершение команд создает основные трудности при обработке исключительных ситуаций. В рассматриваемых в данном разделе машинах с динамическим планированием потока команд прерывания будут неточными, поскольку команды могут завершиться до того, как выполнение более ранней выданной команды вызовет исключительную ситуацию. Таким образом, очень трудно повторить запуск после прерывания. Вместо того, чтобы рассматривать эти проблемы в данном разделе, мы обсудим возможные решения для реализации точных прерываний позже в контексте машин, использующих планирование по предположению.
Чтобы реализовать неупорядоченное выполнение команд, мы расщепляем ступень ID на две ступени:
Затем, как и в рассмотренном нами конвейере, следует ступень EX. Поскольку выполнение команд ПТ может потребовать нескольких тактов в зависимости от типа операции, мы должны знать, когда команда начинает выполняться и когда заканчивается. Это позволяет нескольким командам выполняться в один и тот же момент времени. В дополнение к этим изменениям структуры конвейера мы изменим и структуру функциональных устройств, варьируя количество устройств, задержку операций и степень конвейеризации функциональных устройств так, чтобы лучше использовать эти методы конвейеризации.
Динамическая оптимизация с централизованной схемой обнаружения конфликтов
В конвейере с динамическим планированием выполнения команд все команды проходят через ступень выдачи строго в порядке, предписанном программой (упоря-доченная выдача). Однако они могут приостанавливаться и обходить друг друга на второй ступени (ступени чтения операндов) и тем самым поступать на ступени выполнения неупорядочено. Централизованная схема обнаружения конфликтов представляет собой метод, допускающий неупорядоченное выполнение команд при наличии достаточных ресурсов и отсутствии зависимостей по данным. Впервые подобная схема была применена в компьютере CDC 6600.
Прежде чем начать обсуждение возможности применения подобных схем, важно заметить, что конфликты типа WAR, отсутствующие в простых конвейерах, могут появиться при неупорядоченном выполнении команд. В ранее приведенном примере регистром результата для команды SUBD является регистр R8, который одновременно является источником операнда для команды ADDD. Поэтому здесь между командами ADDD и SUBD имеет место антизависимость: если конвейер выполнит команду SUBD раньше команды ADDD, он нарушит эту антизависимость. Этот конфликт WAR можно обойти, если выполнить два правила: (1) читать регистры только во время стадии чтения операндов и (2) поставить в очередь операцию ADDD вместе с копией ее операндов. Чтобы избежать нарушений зависимостей по выходу конфликты типа WAW (например, это могло произойти, если бы регистром результата команды SUBD была бы регистр F10) все еще должны обнаруживаться. Конфликты типа WAW могут быть устранены с помощью приостановки выдачи команды, регистр результата которой совпадает с уже используемым в конвейере.
Задачей централизованной схемы обнаружения конфликтов является поддержание выполнения команд со скоростью одна команда за такт (при отсутствии структурных конфликтов) посредством как можно более раннего начала выполнения команд. Таким образом, когда команда в начале очереди приостанавливается, другие команды могут выдаваться и выполняться, если они не зависят от уже выполняющейся или приостановленной команды. Централизованная схема несет полную ответственность за выдачу и выполнение команд, включая обнаружение конфликтов. Подобное неупорядоченное выполнение команд требует одновременного нахождения нескольких команд на стадии выполнения. Этого можно достигнуть двумя способами: реализацией в процессоре либо множества неконвейерных функциональных устройств, либо путем конвейеризации всех функциональных устройств. Обе эти возможности по сути эквивалентны с точки зрения организации управления. Поэтому предположим, что в машине имеется несколько неконвейерных функциональных устройств.
Машина CDC 6600 имела 16 отдельных функциональных устройств (4 устройства для операций с плавающей точкой, 5 устройств для организации обращений к основной памяти и 7 устройств для целочисленных операций). В нашем случае централизованная схема обнаружения конфликтов имеет смысл только для устройства плавающей точки. Предположим, что имеются два умножителя, один сложитель, одно устройство деления и одно целочисленное устройство для всех операций обращения к памяти, переходов и целочисленных операций. Хотя устройств в этом примере гораздо меньше, чем в CDC 6600, он достаточно мощный для демонстрации основных принципов работы. Поскольку как наша машина, так и CDC 6600 являются машинами с операциями регистр-регистр (операциями загрузки/записи), в обеих машинах методика практически одинаковая. На рис. 6.3 показана подобная машина.
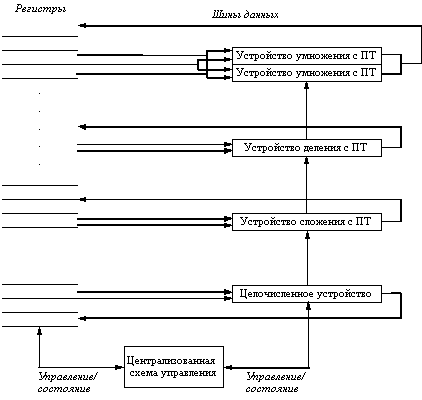
Рис. 6.3. Централизованная схема управления
Каждая команда проходит через централизованную схему обнаружения конфликтов, которая определяет зависимости по данным; этот шаг соответствует стадии выдачи команд и заменяет часть стадии ID в нашем конвейере. Эти зависимости определяют затем моменты времени, когда команда может читать свои операнды и начинать выполнение операции. Если централизованная схема решает, что команда не может немедленно выполняться, она следит за всеми изменениями в аппаратуре и решает, когда команда сможет выполняться. Эта же централизованная схема определяет также когда команда может записать результат в свой регистр результата. Таким образом, все схемы обнаружения и разрешения конфликтов здесь выполняются устройством центрального управления.
Каждая команда проходит четыре стадии своего выполнения. (Поскольку в данный момент мы интересуемся операциями плавающей точки, мы не рассматриваем стадию обращения к памяти). Рассмотрим эти стадии сначала неформально, а затем детально рассмотрим как централизованная схема поддерживает необходимую информацию, которая определяет обработку при переходе с одной стадии на другую. Следующие четыре стадии заменяют стадии ID, EX и WB в стандартном конвейере:
DIVF F0,F2,F4
ADDF F10,F0,F8
SUBF F8,F8,F14
Команда ADDF имеет операнд-источник F8, который является тем же самым регистром, что и регистр результата команды SUBF. Но в действительности команда ADDF зависит от предыдущей команды. Централизованная схема управления будет блокировать выдачу команды SUBF до тех пор, пока команда ADDF не прочитает свои операнды. Тогда в общем случае завершающейся команде не разрешается записывать свои результаты если:
Если этот конфликт типа WAR не существует, централизованная схема управления сообщает функциональному устройству о необходимости записи результата в регистр назначения. Эта стадия заменяет стадию WB в простом конвейере.
Основываясь на своей собственной структуре данных, централизованная схема управления управляет продвижением команды с одной ступени на другую взаимодействуя с функциональными устройствами. Но имеется небольшое усложнение: в регистровом файле имеется только ограниченное число магистралей для операндов-источников и магистралей для записи результата. Централизованная схема управления должна гарантировать, что количество функциональных устройств, которым разрешено продолжать работу на ступенях 2 и 4 не превышает числа доступных шин. Мы не будем вдаваться в дальнейшие подробности и упомянем лишь, что CDC 6600 решала эту проблему путем объединения 16 функциональных устройств друг с другом в четыре группы и поддержки для каждой группы устройств набора шин, называемых магистралями данных (data trunks). Только одно устройство в группе могло читать операнды или записывать свой результат в течение одного такта.
Общая структура регистров состояния устройства централизованного управления показана на рисунке 6.4. Она состоит из 3-х частей:
Интересным вопросом является стоимость и преимущества централизованного управления. Разработчики CDC 6600 оценивают улучшение производительности для программ на Фортране в 1.7 раза, а для вручную запрограммированных на языке ассемблера программ в 2.5 раза. Однако эти оценки делались в то время, когда отсутствовали программные средства планирования загрузки конвейера, полупроводниковая основная память и кэш-память (с малым временем доступа). Централизованная схема управления CDC 6600 имела примерно столько же логических схем, что и одно из функциональных устройств, что на удивление мало. Основная стоимость определялась большим количеством шин (магистралей) - примерно в четыре раза больше по сравнению с машиной, которая выполняла бы команды в строгом порядке, заданном программой.
Централизованная схема управления не обрабатывает несколько ситуаций. Например, когда команда записывает свой результат, зависимая команда в конвейере должна дожидаться разрешения обращения к регистровому файлу, поскольку все результаты всегда записываются в регистровый файл и никогда не используется методика "ускоренной пересылки". Это увеличивает задержку и ограничивает возможность инициирования нескольких команд, ожидающих результата. Что касается CDC 6600, то конфликты типа WAW являются очень редкими, так что приостановки, которые они вызывают, возможно не являются существенными. Однако в следующем разделе мы увидим, что динамическое планирование дает возможность совмещенного выполнения нескольких итераций цикла. Чтобы это делать эффективно, требуется схема обработки конфликтов типа WAW, которые вероятно увеличиваются по частоте при совмещении выполнения нескольких итераций.
| Состояние команд | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда | Выдача | Чтение операндов | Завершение выполнения | Запись результата | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LD | F6,34(R2) | ( | ( | ( | ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LD | F2,45(R3) | ( | ( | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MULTD | F0,F2,F4 | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SUBD | F8,F6,F2 | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DIVD | F10,F0,F6 | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ADD | F6,F8,F2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Состояние функциональных устройств | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Имя | Занятость | Op | Fi | Fj | Fk | Qj | Qk | Rj | Rk | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Integer | Да | Load | F2 | R3 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mult1 | Да | Mult | F0 | F2 | F4 | Нет | Да | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mult2 | Нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add | Да | Sub | F8 | F6 | F2 | Integer | Да | Нет | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Divide | Да | Div | F10 | F0 | F6 | Mult1 | Нет | Да | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Состояние регистра результата | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| F0 | F2 | F4 | F6 | F8 | F10 | F12 | . . . | F30 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| FU | Mult1 | Integer | Add | Divide | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.4. Регистры состояния централизованной схемы управления
Другой подход к динамическому планированию - алгоритм Томасуло
Другой подход к параллельному выполнению команд при наличии конфликтов был использован в устройстве плавающей точки в машине IBM 360/91. Эта схема приписывается Р. Томасуло и названа его именем. Разработка IBM 360/91 была завершена спустя три года после выпуска CDC 6600, прежде чем кэш-память появилась в коммерческих машинах. Задачей IBM было достижение высокой производительности на операциях с плавающей точкой, используя набор команд и компиляторы, разработанные для всего семейства 360, а не только для приложений с интенсивным использованием плавающей точки. Архитектура 360 предусматривала только четыре регистра плавающей точки двойной точности, что ограничивало эффективность планирования кода компилятором. Этот факт был другой мотивацией подхода Томасуло. Наконец, машина IBM 360/91 имела большое время обращения к памяти и большие задержки выполнения операций плавающей точки, преодолеть которые и был призван разработанный Томасуло алгоритм. В конце раздела мы увидим, что алгоритм Томасуло может также поддерживать совмещенное выполнение нескольких итераций цикла.
Мы поясним этот алгоритма на примере устройства ПТ. Основное различие между нашим конвейером ПТ и конвейером машины IBM/360 заключается в наличии в последней машине команд типа регистр-память. Поскольку алгоритм Томасуло использует функциональное устройство загрузки, не требуется значительных изменений, чтобы добавить режимы адресации регистр-память; основное добавление - другая шина. IBM 360/91 имела также конвейерные функциональные устройства, а не несколько функциональных устройств. Единственное отличие между ними заключается в том, что конвейерное функциональное устройство может начинать выполнение только одной операции в каждом такте. Поскольку реально отсутствуют фундаментальные отличия, мы описываем алгоритм, как если бы имели место несколько функциональных устройств. IBM 360/91 могла выполнять одновременно три операции сложения ПТ и две операции умножения ПТ. Кроме того, в процессе выполнения могли находиться до 6 операций загрузки ПТ, или обращений к памяти, и до трех операций записи ПТ. Для реализации этих функций использовались буфера данных загрузки и буфера данных записи. Хотя мы не будем обсуждать устройства загрузки и записи, необходимо добавить буфера для операндов.
Схема Томасуло имеет много общего со схемой централизованного управления CDC 6600, однако имеются и существенные отличия. Во-первых, обнаружение конфликтов и управление выполнением являются распределенными - станции резервирования (reservation stations) в каждом функциональном устройстве определяют, когда команда может начать выполняться в данном функциональном устройстве. В CDC 6600 эта функция централизована. Во-вторых, результаты операций посылаются прямо в функциональные устройства, а не проходят через регистры. В IBM 360/91 имеется общая шина результатов операций (которая называется общей шиной данных (common data bus - CDB)), которая позволяет производить одновременную загрузку всех устройств, ожидающих операнда. CDC 6600 записывает результаты в регистры, за которые ожидающие функциональные устройства могут соперничать. Кроме того, CDC 6600 имеет несколько шин завершения операций (две в устройстве ПТ), а IBM 360/91 - только одну.
На рис. 6.5 представлена основная структура устройства ПТ на базе алгоритма Томасуло. Никаких таблиц управления выполнением не показано. Станции резервирования хранят команды, которые выданы и ожидают выполнения в соответствующем функциональном устройстве, а также информацию, требующуюся для управления командой, когда ее выполнение началось в функциональном устройстве. Буфера загрузки и записи хранят данные поступающие из памяти и записываемые в память. Регистры ПТ соединены с функциональными устройствами парой шин и одной шиной с буферами записи. Все результаты из функциональных устройств и из памяти посылаются на общую шину данных, которая связана со входами всех устройств за исключением буфера загрузки. Все буфера и станции резервирования имеют поля тегов, используемых для управления конфликтами.
Прежде чем описывать детали станций резервирования и алгоритм, рассмотрим все стадии выполнения команды. В отличие от централизованной схемы управления, имеется всего три стадии:
Хотя эти шаги в основном похожи на аналогичные шаги в централизованной схеме управления, имеются три важных отличия. Во-первых, отсутствует контроль конфликтов типа WAW и WAR - они устраняются как побочный эффект алгоритма. Во-вторых, для трансляции результатов используется CDB, а не схема ожидания готовности регистров. В-третьих, устройства загрузки и записи рассматриваются как основные функциональные устройства.
Структуры данных, используемые для обнаружения и устранения конфликтов, связаны со станциями резервирования, регистровым файлом и буферами загрузки и записи. Хотя с разными объектами связана разная информация, все устройства, за исключением буферов загрузки, содержат в каждой строке поле тега. Это поле тега представляет собой четырехбитовое значение, которое обозначает одну из пяти станций резервирования или один из шести буферов загрузки. Поле тега используется для описания того, какое функциональное устройства будет поставлять результат, нужный в качестве источника операнда. Неиспользуемые значения, такие как ноль, показывают что операнд уже доступен. Важно помнить, что теги в схеме Томасуло ссылаются на буфера или устройства, которые будут поставлять результат; когда команда выдается в станцию резервирования номера регистров исключаются из рассмотрения.
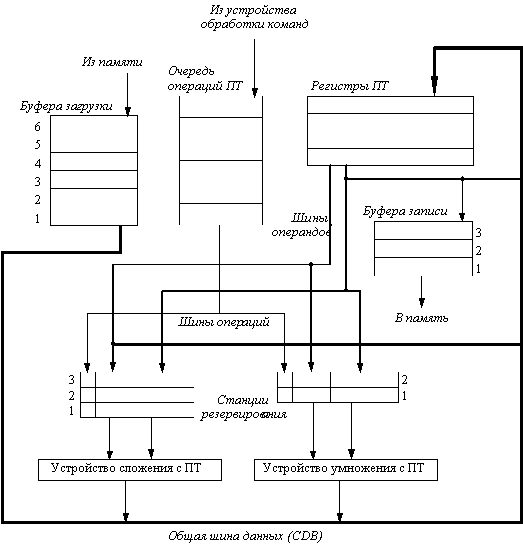
Рис. 6.5. Структура устройства ПТ на основе алгоритма Томасуло
Каждая станция резервирования содержит шесть полей:
Регистровый файл и буфер записи имеют поле Qi:
В каждом из буферов загрузки и записи требуется поле занятости, показывающее когда соответствующий буфер становится доступным благодаря завершению загрузки или записи, назначенных на этот буфер. Буфер записи имеет также поле V для хранения значения, которое должно быть записано в память.
Прежде, чем мы исследуем алгоритм в деталях, давайте посмотрим как выглядят системные таблицы для следующей последовательности команд:
1. LF F6,34(R2)
2. LF F2,45(R3)
3. MULTD F0,F2,F4
4. SUBD F8,F6,F2
5. DIVD F10,F0,F6
6. ADDD F6,F8,F2
Рис. 6.6 описывает станции резервирования, буфера загрузки и записи и регистровые теги. К именам add, mult и load добавлены номера, стоящие за тегами для этой станции резервирования - Add1 является тегом для результата из первого устройства сложения. Состояние каждой операции, которая выдана для выполнения, хранится в станции резервирования.
| Состояние команд | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда | Выдача | Выполнение | Запись результата | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LD | F6,34(R2) | ( | ( | (+ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LD | F2,45(R3) | ( | ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MULTD | F0,F2,F4 | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SUBD | F8,F6,F2 | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DIVD | F10,F0,F6 | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ADDD | F6,F8,F2 | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Станции резервирования | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Имя | Занятость | Op | Vj | Vk | Qj | Qk | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add1 | Да | SUB | Mem[34+Regs[R2]] | Load2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add2 | Да | ADD | Add1 | Load2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add3 | Нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mult1 | Да | MULT | Regs[F4] | Load2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mult2 | Да | DIV | Mem[34+Regs[R2]] | Mult1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Состояние регистров | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Поле | F0 | F2 | F4 | F6 | F8 | F10 | F12 | . . . | F30 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Qi | Mult1 | Load2 | Add2 | Add1 | Mult2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.6. Теги станций резервирования и регистров
Имеются два важных отличия от централизованной схемы управления, которые заметны в этих таблицах. Во-первых, значение операнда хранится в станции резервирования в одном из полей V как только оно становится доступным; оно не считывается из регистрового файла во время выдачи команды. Во-вторых, команда ADDD выдана для выполнения. Ее выдача была заблокирована в централизованной схеме управления из-за наличия структурного конфликта.
Большие преимущества схемы Томасуло заключаются в (1) распределении логики обнаружения конфликтов, и (2) устранение приостановок, связанных с конфликтами типа WAW и WAR. Первое преимущество возникает из-за наличия распределенных станций резервирования и использования CDB. Если несколько команд ожидают один и тот же результат и каждая команда уже имеет свой другой операнд, то команды могут выдаваться одновременно посредством трансляции по CDB. В централизованной схеме управления ожидающие команды должны читать свои операнды из регистров когда станут доступными регистровые шины.
Конфликты типа WAW и WAR устраняются путем переименования регистров используя станции резервирования. Например, в нашей кодовой последовательности на рис. 6.6 мы выдали на выполнение как команду DIVD, так и команду ADDD, даже хотя имелся конфликт типа WAR по регистру F6. Конфликт устраняется одним из двух способов. Если команда, поставляющая значение для команды DIVD, завершилась, тогда Vk будет хранить результат, позволяя DIVD выполняться независимо от команды ADDD. С другой стороны, если выполнение команды LF не завершилось, то Qk будет указывать на LOAD1 и команда DIVD будет независимой от ADDD. Таким образом, в любом случае команда ADDD может быть выдана и начать выполняться. Любое использование результата команды MULTD будет указывать на станцию резервирования, позволяя ADDD завершить и записать свое значение в регистры без воздействия DIVD. Вскоре мы увидим пример устранения конфликта типа WAW.
Чтобы понять полную мощность устранения конфликтов типа WAW и WAR посредством динамического переименования регистров мы должны рассмотреть цикл. Рассмотрим следующую простую последовательность команд для умножения элементов вектора на скалярную величину, находящуюся в регистре F2:
Loop: LD F0,0(R1)
MULTD F4,F0,F2
SD 0(R1),F4
SUBI R1,R1,#8
BNEZ R1,Loop ; условный переход при R1 /=0
Со стратегией выполняемого перехода использование станций резервирования позволит сразу же продолжить выполнение нескольких итераций этого цикла. Это преимущество дается без статического разворачивания цикла программными средствами: в действительности цикл разворачивается динамически аппаратурой. В архитектуре 360 наличие всего 4 регистров ПТ сильно ограничивало бы использование статического разворачивания цикла. (Вскоре мы увидим, что при статическом разворачивании и планировании выполнения цикла для обхода взаимных блокировок требуется значительно большее число регистров). Алгоритм Томасуло поддерживает выполнение с перекрытием нескольких копий одного и того же цикла при наличии лишь небольшого числа регистров, используемых программой.
Давайте предположим, что мы выдали для выполнения все команды двух последовательных итераций цикла, но еще не завершилось выполнение ни одной операции загрузки/записи в память. Станции резервирования, таблицы состояния регистров и буфера загрузки/записи в этой точке показаны на рис. 6.7. (Здесь операции целочисленного АЛУ игнорируются и предполагается, что условный переход был спрогнозирован как выполняемый). Когда система достигла такого состояния могут поддерживаться две копии цикла с CPI близким к единице при условии, что операции умножения могут завершиться за четыре такта. Если мы игнорируем накладные расходы цикла, которые не снижены в этой схеме, достигнутый уровень производительности будет соответствовать тому, который мы могли бы достигнуть посредством статического разворачивания и планирования цикла компилятором при условии наличия достаточного числа регистров.
В этом примере показан дополнительный элемент, который является важным для того, чтобы алгоритм Томасуло работал. Команда загрузки из второй итерации цикла может легко закончиться раньше команды записи из первой итерации, хотя нормальный последовательный порядок отличается. Загрузка и запись могут надежно (безопасно) выполняться в различном порядке при условии, что загрузка и запись обращаются к разным адресам. Это контролируется путем проверки адресов в буфере записи каждый раз при выдаче команды загрузки. Если адрес команды загрузки соответствует одному из адресов в буфере записи мы должны остановиться и подождать до тех пор, пока буфер записи не получит требуемое значение; затем мы можем к нему обращаться или выбирать значение из памяти. Это динамическое сравнение адресов является альтернативой технике, которая может использоваться компилятором при перестановке команд загрузки и записи.
| Состояние команд | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда | Номер итерации | Выдача | Выполнение | Запись результата | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LD | F0,0(R1) | 1 | ( | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MULTD | F4,F0,F2 | 1 | ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SD | 0(R1),F4 | 1 | ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LD | F0,0(R1) | 2 | ( | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MULTD | F4,F0,F2 | 2 | ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SD | 0(R1),F4 | 2 | ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Станции резервирования | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Имя | Занятость | Fm | Vj | Vk | Qj | Qk | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add1 | Нет | Mem[34+Regs[R2]] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add2 | Нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Add3 | Нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mult1 | Да | MULT | Regs[F2] | Load1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mult2 | Да | MULT | Regs[F2] | Load2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Состояние регистров | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Поле | F0 | F2 | F4 | F6 | F8 | F10 | F12 | . . . | F30 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Qi | Load2 | Mult2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Буфера загрузки | Буфера записи | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Поле | Load1 | Load2 | Load3 | Поле | Store1 | Store2 | Store3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Адрес | Regs[R1] | Regs[R1]-8 | Qi | Mult1 | Mult2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Заня-тость | Да | Да | Нет | Заня-тость | Да | Да | Нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Адрес | Regs[R1] | Regs[R1]-8 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.7. Состояние станций резервирования, регистров и буферов загрузки/записи
Эта динамическая схема может достигать очень высокой производительности при условии того, что стоимость переходов может поддерживаться небольшой. Этот вопрос мы будем рассматривать в следующем разделе. Главный недостаток этого подхода заключается в сложности схемы Томасуло, которая требует для своей реализации очень большого объема аппаратуры. Особенно это касается большого числа устройств ассоциативной памяти, которая должна работать с высокой скоростью, а также сложной логики управления. Наконец, увеличение производительности ограничивается наличием одной шины завершения (CDB). Хотя дополнительные шины CDB могут быть добавлены, каждая CDB должна взаимодействовать со всей аппаратурой конвейера, включая станции резервирования. В частности, аппаратуру ассоциативного сравнения необходимо дублировать на каждой станции для каждой CDB.
В схеме Томасуло комбинируются две различных методики: методика переименования регистров буферизация операндов-источников из регистрового файла. Буферизация источников операндов разрешает конфликты типа WAR, которые возникают когда операнды доступны в регистрах. Как мы увидим позже, возможно также устранять конфликты типа WAR посредством переименования регистра вместе с буферизацией результата до тех пор, пока остаются обращения к старой версии регистра; этот подход будет использоваться, когда мы будем обсуждать аппаратное выполнение по предположению.
Схема Томасуло является привлекательной, если разработчик вынужден делать конвейерную архитектуру, для которой трудно выполнить планирование кода или реализовать большое хранилище регистров. С другой стороны, преимущество подхода Томасуло возможно ощущается меньше, чем увеличение стоимости реализации, по сравнению с методами планирования загрузки конвейера средствами компилятора в машинах, ориентированных на выдачу для выполнения только одной команды в такте. Однако по мере того, как машины становятся все более агрессивными в своих возможностях выдачи команд и разработчики сталкиваются с вопросами производительности кода, который трудно планировать (большинство кодов для нечисловых расчетов), методика типа переименования регистров и динамического планирования будет становиться все более важной. Позже в этой главе мы увидим, что эти методы являются одним из важных компонентов большинства схем для реализации аппаратного выполнения по предположению.
Ключевыми компонентами увеличения параллелизма уровня команд в алгоритме Томасуло являются динамическое планирование, переименование регистров и динамическое устранение неоднозначности обращений к памяти. Трудно оценить значение каждого из этих свойств по отдельности.
Динамической аппаратной технике планирования загрузки конвейера при наличии зависимостей по данным соответствует и динамическая техника для эффективной обработки переходов. Эта техника используется для двух целей: для прогнозирования того, будет ли переход выполняемым, и для возможно более раннего нахождения целевой команды перехода. Эта техника называется аппаратным прогнозированием переходов.
Буфера прогнозирования условных переходов
Простейшей схемой динамического прогнозирования направления условных переходов является буфер прогнозирования условных переходов (branch-prediction buffer) или таблица "истории" условных переходов (branch history table). Буфер прогнозирования условных переходов представляет собой небольшую память, адресуемую с помощью младших разрядов адреса команды перехода. Каждая ячейка этой памяти содержит один бит, который говорит о том, был ли предыдущий переход выполняемым или нет. Это простейший вид такого рода буфера. В нем отсутствуют теги, и он оказывается полезным только для сокращения задержки перехода в случае, если эта задержка больше, чем время, необходимое для вычисления значения целевого адреса перехода. В действительности мы не знаем, является ли прогноз корректным (этот бит в соответствующую ячейку буфера могла установить совсем другая команда перехода, которая имела то же самое значение младших разрядов адреса). Но это не имеет значения. Прогноз - это только предположение, которое рассматривается как корректное, и выборка команд начинается по прогнозируемому направлению. Если же предположение окажется неверным, бит прогноза инвертируется. Конечно такой буфер можно рассматривать как кэш-память, каждое обращение к которой является попаданием, и производительность буфера зависит от того, насколько часто прогноз применялся и насколько он оказался точным.
Однако простая однобитовая схема прогноза имеет недостаточную производительность. Рассмотрим, например, команду условного перехода в цикле, которая являлась выполняемым переходом последовательно девять раз подряд, а затем однажды невыполняемым. Направление перехода будет неправильно предсказываться при первой и при последней итерации цикла. Неправильный прогноз последней итерации цикла неизбежен, поскольку бит прогноза будет говорить, что переход "выполняемый" (переход был девять раз подряд выполняемым). Неправильный прогноз на первой итерации происходит из-за того, что бит прогноза инвертируется при предыдущем выполнении последней итерации цикла, поскольку в этой итерации переход был невыполняемым. Таким образом, точность прогноза для перехода, который выполнялся в 90% случаев, составила только 80% (2 некорректных прогноза и 8 корректных). В общем случае, для команд условного перехода, используемых для организации циклов, переход является выполняемым много раз подряд, а затем один раз оказывается невыполняемым. Поэтому однобитовая схема прогнозирования будет неправильно предсказывать направление перехода дважды (при первой и при последней итерации).
Для исправления этого положения часто используется схема двухбитового прогноза. В двухбитовой схеме прогноз должен быть сделан неверно дважды, прежде чем он изменится на противоположное значение. На рис. 6.8 представлена диаграмма состояний двухбитовой схемы прогнозирования направления перехода.
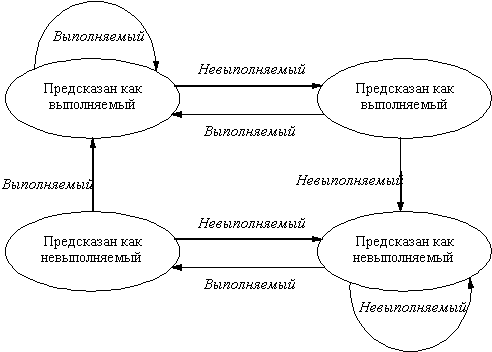
Рис. 6.8. Диаграмма состояния двухбитовой схемы прогнозирования
Двухбитовая схема прогнозирования в действительности является частным случаем более общей схемы, которая в каждой строке буфера прогнозирования имеет n-битовый счетчик. Этот счетчик может принимать значения от 0 до 2n - 1. Тогда схема прогноза будет следующей:
Исследования n-битовых схем прогнозирования показали, что двухбитовая схема работает почти также хорошо, и поэтому в большинстве систем применяются двухбитовые схемы прогноза, а не n-битовые.
Буфер прогнозирования переходов может быть реализован в виде небольшой специальной кэш-памяти, доступ к которой осуществляется с помощью адреса команды во время стадии выборки команды в конвейере (IF), или как пара битов, связанных с каждым блоком кэш-памяти команд и выбираемых с каждой командой. Если команда декодируется как команда перехода, и если переход спрогнозирован как выполняемый, выборка команд начинается с целевого адреса как только станет известным новое значение счетчика команд. В противном случае продолжается последовательная выборка и выполнение команд. Если прогноз оказался неверным, значение битов прогноза меняется в соответствии с рис. 6.8. Хотя эта схема полезна для большинства конвейеров, рассмотренный нами простейший конвейер выясняет примерно за одно и то же время оба вопроса: является ли переход выполняемым и каков целевой адрес перехода (предполагается отсутствие конфликта при обращении к регистру, определенному в команде условного перехода. Напомним, что для простейшего конвейера это справедливо, поскольку условный переход выполняет сравнение содержимого регистра с нулем во время стадии ID, во время которой вычисляется также и эффективный адрес). Таким образом, эта схема не помогает в случае простых конвейеров, подобных рассмотренному ранее.
Как уже упоминалось, точность двухбитовой схемы прогнозирования зависит от того, насколько часто прогноз каждого перехода является правильным и насколько часто строка в буфере прогнозирования соответствует выполняемой команде перехода. Если строка не соответствует данной команде перехода, прогноз в любом случае делается, поскольку все равно никакая другая информация не доступна. Даже если эта строка соответствует совсем другой команде перехода, прогноз может быть удачным.
Какую точность можно ожидать от буфера прогнозирования переходов на реальных приложениях при использовании 2 бит на каждую строку буфера? Для набора оценочных тестов SPEC-89 буфер прогнозирования переходов с 4096 строками дает точность прогноза от 99% до 82%, т.е. процент неудачных прогнозов составляет от 1% до 18% (см. рис. 6.9). Следует отметить, что буфер емкостью 4К строк считается очень большим. Буферы меньшего объема дадут худшие результаты.
Однако одного знания точности прогноза не достаточно для того, чтобы определить воздействие переходов на производительность машины, даже если известны время выполнения перехода и потери при неудачном прогнозе. Необходимо учитывать частоту переходов в программе, поскольку важность правильного прогноза больше в программах с большей частотой переходов. Например, целочисленные программы li, eqntott, expresso и gcc имеют большую частоту переходов, чем значительно более простые для прогнозирования программы плавающей точки nasa7, matrix300 и tomcatv.
Поскольку главной задачей является использование максимально доступной степени параллелизма программы, точность прогноза направления переходов становится очень важной. Как видно из рис. 6.9, точность схемы прогнозирования для целочисленных программ, которые обычно имеют более высокую частоту переходов, меньше, чем для научных программ с плавающей точкой, в которых интенсивно используются циклы. Можно решать эту проблему двумя способами: увеличением размера буфера и увеличением точности схемы, которая используется для выполнения каждого отдельного прогноза. Буфер с 4К строками уже достаточно большой и, как показывает рис. 6.9, работает практически также, что и буфер бесконечного размера. Из этого рисунка становится также ясно, что коэффициент попаданий буфера не является лимитирующим фактором. Как мы упоминали выше, увеличение числа бит в схеме прогноза также имеет малый эффект.
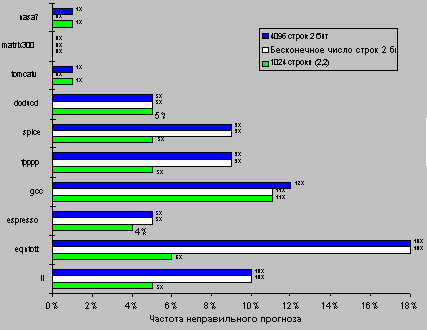
Рис. 6.9. Сравнение качества 2-битового прогноза
Рассмотренные двухбитовые схемы прогнозирования используют информацию о недавнем поведении команды условного перехода для прогноза будущего поведения этой команды. Вероятно можно улучшить точность прогноза, если учитывать не только поведение того перехода, который мы пытаемся предсказать, но рассматривать также и недавнее поведение других команд перехода. Рассмотрим, например, небольшой фрагмент из текста программы eqntott тестового пакета SPEC92 (это наихудший случай для двухбитовой схемы прогноза):
if (aa==2)
aa=0;
if (bb==2)
bb=0;
if (aa!=bb) {
Ниже приведен текст сгенерированной программы (предполагается, что aa и bb размещены в регистрах R1 и R2):
SUBI R3,R1,#2
BNEZ R3,L1 ; переход b1 (aa!=2)
ADD R1,R0,R0 ; aa=0
L1: SUBI R3,R2,#2
BNEZ R3,L2 ; переход b2 (bb!=2)
ADD R2,R0,R0 ; bb=0
L2: SUB R3,R1,R2 ; R3=aa-bb
BEQZ R3,L3 ; branch b3 (aa==bb).
...
L3:
Пометим команды перехода как b1, b2 и b3. Можно заметить, что поведение перехода b3 коррелирует с переходами b1 и b2. Ясно, что если оба перехода b1 и b2 являются невыполняемыми (т.е. оба условия if оцениваются как истинные и обеим переменным aa и bb присвоено значение 0), то переход b3 будет выполняемым, поскольку aa и bb очевидно равны. Схема прогнозирования, которая для предсказания направления перехода использует только прошлое поведение того же перехода никогда этого не учтет.
Схемы прогнозирования, которые для предсказания направления перехода используют поведение других команд перехода, называются коррелированными или двухуровневыми схемами прогнозирования. Схема прогнозирования называется прогнозом (1,1), если она использует поведение одного последнего перехода для выбора из пары однобитовых схем прогнозирования на каждый переход. В общем случае схема прогнозирования (m,n) использует поведение последних m переходов для выбора из 2m схем прогнозирования, каждая из которых представляет собой n-битовую схему прогнозирования для каждого отдельного перехода. Привлекательность такого типа коррелируемых схем прогнозирования переходов заключается в том, что они могут давать больший процент успешного прогнозирования, чем обычная двухбитовая схема, и требуют очень небольшого объема дополнительной аппаратуры. Простота аппаратной схемы определяется тем, что глобальная история последних m переходов может быть записана в m-битовом сдвиговом регистре, каждый разряд которого запоминает, был ли переход выполняемым или нет. Тогда буфер прогнозирования переходов может индексироваться конкатенацией (объединением) младших разрядов адреса перехода с m-битовой глобальной историей. Например, на рис. 6.10. показана схема прогнозирования (2,2) и организация выборки битов прогноза.
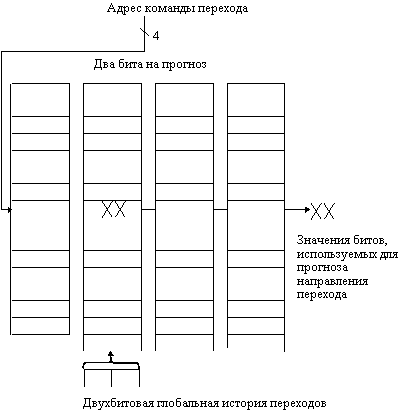
Рис. 6.10. Буфер прогнозирования переходов (2,2)
В этой реализации имеется тонкий эффект: поскольку буфер прогнозирования не является кэш-памятью, счетчики, индексируемые единственным значением глобальной схемы прогнозирования, могут в действительности в некоторый момент времени соответствовать разным командам перехода; это не отличается от того, что мы видели и раньше: прогноз может не соответствовать текущему переходу. На рис. 6.10 с целью упрощения понимания буфер изображен как двумерный объект. В действительности он может быть реализован просто как линейный массив двухбитовой памяти; индексация выполняется путем конкатенации битов глобальной истории и соответствующим числом бит, требуемых от адреса перехода. Например, на рис. 6.9 в буфере (2,2) с общим числом строк, равным 64, четыре младших разряда адреса команды перехода и два бита глобальной истории формируют 6-битовый индекс, который может использоваться для обращения к 64 счетчикам.
Насколько лучше схемы с корреляцией переходов работают по сравнению со стандартной духбитовой схемой? Чтобы их справедливо сравнить, нужно сопоставить схемы прогнозирования, использующие одинаковое число бит состояния. Число бит в схеме прогнозирования (m,n) равно 2m ( n ( количество строк, выбираемых с помощью адреса перехода.
Например, двухбитовая схема прогнозирования без глобальной истории есть просто схема (0,2). Сколько бит требуется для реализации схемы прогнозирования (0,2), которую мы рассматривали раньше? Сколько бит используется в схеме прогнозирования, показанной на рис. 6.10?
Раньше мы рассматривали схему прогнозирования с 4К строками, выбираемыми адресом перехода. Таким образом общее количество бит равно: 20 ( 2 ( 4K = 8K.
Схема на рис. 6.10. имеет 22 ( 2 ( 16 = 128 бит.
Чтобы сравнить производительность схемы коррелированного прогнозирования с простой двухбитовой схемой прогнозирования, производительность которой была представлена на рис. 6.8, нужно определить количество строк в схеме коррелированного прогнозирования.
Таким образом, мы должны определить количество строк, выбираемых командой перехода в схеме прогнозирования (2,2), которая содержит 8К бит в буфере прогнозирования.
Мы знаем, что
22 ( 2 ( количество строк, выбираемых
командой перехода = 8К
Поэтому
Количество строк, выбираемых командой
перехода = 1К.
На рис. 6.9 представлены результаты для сравнения простой двухбитовой схемы прогнозирования с 4К строками и схемы прогнозирования (2,2) с 1К строками. Как можно видеть, эта последняя схема прогнозирования не только превосходит простую двухбитовую схему прогнозирования с тем же самым количеством бит состояния, но часто превосходит даже двухбитовую схему прогнозирования с неограниченным (бесконечным) количеством строк. Имеется широкий спектр корреляционных схем прогнозирования, среди которых схемы (0,2) и (2,2) являются наиболее интересными.
Дальнейшее уменьшение приостановок по управлению: буфера целевых адресов переходов
Рассмотрим ситуацию, при которой на стадии выборки команд находится команда перехода (на следующей стадии будет осуществляться ее дешифрация). Тогда чтобы сократить потери, необходимо знать, по какому адресу выбирать следующую команду. Это означает, что нам как-то надо выяснить, что еще недешифрированная команда в самом деле является командой перехода, и чему равно следующее значение счетчика адресов команд. Если все это мы будем знать, то потери на команду перехода могут быть сведены к нулю. Специальный аппаратный кэш прогнозирования переходов, который хранит прогнозируемый адрес следующей команды, называется буфером целевых адресов переходов (branch-target buffer).
Каждая строка этого буфера включает программный адрес команды перехода, прогнозируемый адрес следующей команды и предысторию команды перехода (рис. 6.11). Биты предыстории представляют собой информацию о выполнении или невыполнении условий перехода данной команды в прошлом. Обращение к буферу целевых адресов перехода (сравнение с полями программных адресов команд перехода) производится с помощью текущего значения счетчика команд на этапе выборки очередной команды. Если обнаружено совпадение (попадание в терминах кэш-памяти), то по предыстории команды прогнозируется выполнение или невыполнение условий команды перехода, и немедленно производится выборка и дешифрация команд из прогнозируемой ветви программы. Считается, что предыстория перехода, содержащая информацию о двух предшествующих случаях выполнения этой команды, позволяет прогнозировать развитие событий с вполне достаточной вероятностью.
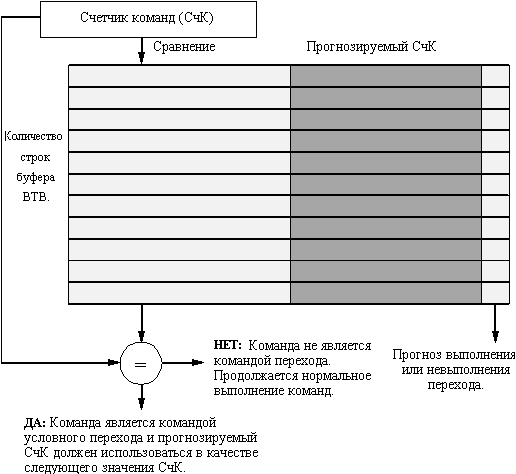
Рис. 6.11. Буфер целевых адресов переходов
Существуют и некоторые вариации этого метода. Основной их смысл заключается в том, чтобы хранить в процессоре одну или несколько команд из прогнозируемой ветви перехода. Этот метод может применяться как в совокупности с буфером целевых адресов перехода, так и без него, и имеет два преимущества. Во-первых, он позволяет выполнять обращения к буферу целевых адресов перехода в течение более длительного времени, а не только в течение времени последовательной выборки команд. Это позволяет реализовать буфер большего объема. Во-вторых, буферизация самих целевых команд позволяет использовать дополнительный метод оптимизации, который называется свертыванием переходов (branch folding). Свертывание переходов может использоваться для реализации нулевого времени выполнения самих команд безусловного перехода, а в некоторых случаях и нулевого времени выполнения условных переходов. Рассмотрим буфер целевых адресов перехода, который буферизует команды из прогнозируемой ветви. Пусть к нему выполняется обращение по адресу команды безусловного перехода. Единственной задачей этой команды безусловного перехода является замена текущего значения счетчика команд. В этом случае, когда буфер адресов регистрирует попадание и показывает, что переход безусловный, конвейер просто может заменить команду, которая выбирается из кэш-памяти (это и есть сама команда безусловного перехода), на команду из буфера. В некоторых случаях таким образом удается убрать потери для команд условного перехода, если код условия установлен заранее.
Еще одним методом уменьшения потерь на переходы является метод прогнозирования косвенных переходов, а именно переходов, адрес назначения которых меняется в процессе выполнения программы (в run-time). Компиляторы языков высокого уровня будут генерировать такие переходы для реализации косвенного вызова процедур, операторов select или case и вычисляемых операторов goto в Фортране. Однако подавляющее большинство косвенных переходов возникает в процессе выполнения программы при организации возврата из процедур. Например, для тестовых пакетов SPEC возвраты из процедур в среднем составляют 85% общего числа косвенных переходов.
Хотя возвраты из процедур могут прогнозироваться с помощью буфера целевых адресов переходов, точность такого метода прогнозирования может оказаться низкой, если процедура вызывается из нескольких мест программы или вызовы процедуры из одного места программы не локализуются по времени. Чтобы преодолеть эту проблему, была предложена концепция небольшого буфера адресов возврата, работающего как стек. Эта структура кэширует последние адреса возврата: во время вызова процедуры адрес возврата вталкивается в стек, а во время возврата он оттуда извлекается. Если этот кэш достаточно большой (например, настолько большой, чтобы обеспечить максимальную глубину вложенности вызовов), он будет прекрасно прогнозировать возвраты. На рис. 6.12 показано исполнение такого буфера возвратов, содержащего от 1 до 16 строк (элементов) для нескольких тестов SPEC.
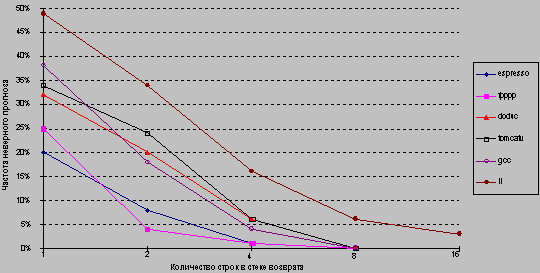
Рис. 6.12. Точность прогноза для адресов возврата
Точность прогноза в данном случае есть доля адресов возврата, предсказанных правильно. Поскольку глубина вызовов процедур обычно не большая, за некоторыми исключениями даже небольшой буфер работает достаточно хорошо. В среднем возвраты составляют 81% общего числа косвенных переходов для этих шести тестов.
Схемы прогнозирования условных переходов ограничены как точностью прогноза, так и потерями в случае неправильного прогноза. Как мы видели, типичные схемы прогнозирования достигают точности прогноза в диапазоне от 80 до 95% в зависимости от типа программы и размера буфера. Кроме увеличения точности схемы прогнозирования, можно пытаться уменьшить потери при неверном прогнозе. Обычно это делается путем выборки команд по обоим ветвям (по предсказанному и по непредсказанному направлению). Это требует, чтобы система памяти была двухпортовой, включала кэш-память с расслоением, или осуществляла выборку по одному из направлений, а затем по другому (как это делается в IBM POWER-2). Хотя подобная организация увеличивает стоимость системы, возможно это единственный способ снижения потерь на условные переходы ниже определенного уровня. Другое альтернативное решение, которое используется в некоторых машинах, заключается в кэшировании адресов или команд из нескольких направлений (ветвей) в целевом буфере.