
В предыдущих разделах данной главы мы говорили о недостатках реляционных СУБД и способах их преодоления. Теперь настала пора обсудить некоторые более общие вопросы использования баз данных и их поддержки вычислительными архитектурами.
Компьютеры, как известно, были созданы для удовлетворения потребностей исследователей, решавших вычислительные задачи. Однако, со временем все чаще и чаще они стали использоваться для решения невычислительных задач, а именно для хранения, поиска и преобразования документов (инофрмации). Когда компьютеры стали широко применяться в таких задачах, обнаружилась неприспособленность их традиционной (фоннеймановской) архитектуры для этих целей.
Архитектура компьютера, разработанная Дж. Фон Нейманом показана на следующем рисунке.
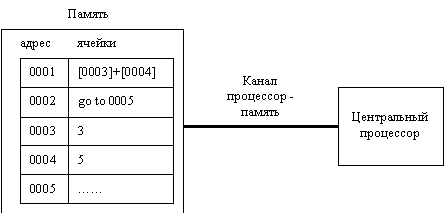
В качестве примера рассмотрим фрагмент программы, связанный с обработкой массива:
for i=1 to 10 do a[i]=a[i]+b[i];При обращении к массиву компьютер определяет начальный адрес массива и по значению индекса выбирает его конкретный элемент (адрес элемента = начальный адрес + смещение).
Теперь рассмотрим пример, связанный с выборкой из базы данных:
SELECT имя FROM служащие WHERE возраст < 35 AND зарплата > 400Здесь имена служащих выбираются из файла не по адресу, а по содержимому полей "возраст" и "зарплата". Этот способ адресации называется ассоциативным обращением или ассоциативной адресацией.
Поскольку в современных компьютерах для нечисловой обработки используется та же архитектура, что и для числовой, используются методы эмуляции ассоциативного доступа - создается специальная таблица для перевода ассоциативного запроса в соответствующий адрес - индекс.
В общем виде архитектура нечисловой обработки должна удовлетворять следующим требованиям:
К сожалению, до настоящего времени не достигнуто больших успехов в создании ассоциативных систем. Более подробно с этим вопросом можно ознакомиться в книге Э.Озкарахана (см. список литературы).