
Как правило компьютеры и программы, входящие в состав информационной системы, не являются равноправными. Некоторые из них владеют ресурсами (файловая система, процессор, принтер, база данных и т.д.), другие имеют возможность обращаться к этим ресурсам. Компьютер (или программу), управляющий ресурсом, называют сервером этого ресурса (файл-сервер, сервер базы данных, вычислительный сервер...). Клиент и сервер какого-либо ресурса могут находится как в рамках одной вычислительной системы, так и на различных компьютерах, связанных сетью.
Основной принцип технологии "клиент-сервер" заключается в разделении функций приложения на три группы:
Компанией Gartner Group, специализирующейся в области исследования информационных технологий, предложена следующая классификация двухзвенных моделей взаимодействия клиент-сервер (двухзвенными эти модели называются потому, что три компонента приложения различным образом распределяются между двумя узлами):
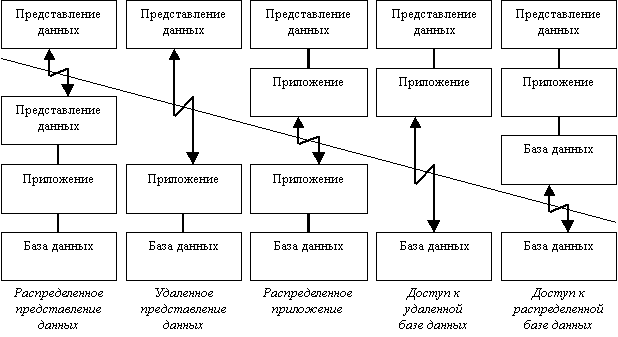
Исторически первой появилась модель распределенного представления данных, которая реализовывалась на универсальной ЭВМ с подключенными к ней неинтеллектуальными терминалами. Управление данными и взаимодействие с пользователем при этом объединялись в одной программе, на терминал передавалась только "картинка", сформированная на центральном компьютере.
Затем, с появлением персональных компьютеров (ПК) и локальных сетей, были реализованы модели доступа к удаленной базе данных. Некоторое время базовой для сетей ПК была архитектура файлового сервера. При этом один из компьютеров является файловым сервером, на клиентах выполняются приложения, в которых совмещены компонент представления и прикладной компонент (СУБД и прикладная программма). Протокол обмена при этом представляет набор низкоуровненых вызовов операций файловой системы. Такая архитектура, реализуемая, как правило, с помощью персональных СУБД (см. параграф 4.8), имеет очевидные недостатки - высокий сетевой трафик и отсутствие унифицированного доступа к ресурсам.
С появлением первых специализированных серверов баз данных появилась возможность другой реализации модели доступа к удаленной базе данных. В этом случае ядро СУБД функционирует на сервере, протокол обмена обеспечивается с помощью языка SQL. Такой подход по сравнению с файловым сервером ведет к уменьшению загрузки сети и унификации интерфейса "клиент-сервер". Однако, сетевой трафик остается достаточно высоким, кроме того, по прежнему невозможно удовлетворительное администрирование приложений, поскольку в одной программе совмещаются различные функции.
Позже была разработана концепция активного сервера, который использовал механизм хранимых процедур. Это позволило часть прикладного компонента перенести на сервер (модель распределенного приложения). Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, что и SQL-сервер. Преимущества такого подхода: возможно централизованное администрирование прикладных функций, значительно снижается сетевой трафик (т.к. передаются не SQL-запросы, а вызовы хранимых процедур). Недостаток - ограниченность средств разработки хранимых процедур по сравнению с языками общего назначения (C и Pascal).
На практике сейчас обычно используются смешанный подход:
Сейчас ряд поставщиков коммерческих СУБД объявило о планах реализации механизмов выполнения хранимых процедур с использованием языка Java. Это соответствует концепции "тонкого клиента", функцией которого остается только отображение данных (модель удаленного представления данных).
В последнее время также наблюдается тенденция ко все большему использованию модели распределенного приложения. Характерной чертой таких приложений является логическое разделение приложения на две и более частей, каждая из которых может выполняться на отдельном компьютере. Выделенные части приложения взаимодействуют друг с другом, обмениваясь сообщениями в заранее согласованном формате. В этом случае двухзвенная архитектура клиент-сервер становится трехзвенной, а к некоторых случаях, она может включать и больше звеньев.

В том случае, когда информационная система объединяет достаточно большое количество различных информационных ресурсов и серверов приложений, встает вопрос об оптимальном управлении всеми ее компонентами. В этом случае используют специализированные средства - мониторы обработки транзакций (часто их называют просто "мониторы транзакций"). При этом понятие транзакции расширяется по сравнению с используемым в теории баз данных. В данном случае это не атомарное действие над базой данных, а любое действие в системе - выдача сообщения, запись в индексный файл, печать отчета и т.д.
Для общения прикладной программы с монитором транзакций используется специализированный API (Application Program Interface - интерфейс прикладного программмирования), который реализуется в виде библиотеки, содержащей вызовы основных функций (установить соединение, вызвать определенный сервис и т.д.). Серверы приложений (сервисы) также создаются с помощью этого API, каждому сервису присваивается уникальное имя. Монитор транзакций, получив запрос от прикладной программы, передает ее вызов соответствующему сервису (если тот не запущен, порождается необходимый процесс), после обработки запроса сервером приложений возвращает результаты клиенту. Для взаимодействия мониторов транзакций с серверами баз данных разработан протокол XA. Наличие такого унифицированного интерфейса позволяет использовать в рамках одного приложения несколько различных СУБД.
Использование мониторов транзакций в больших системах дает следующие преимущества: